今天算是一个比较清闲的下午,还能够静下心来总结梳理一下,真是难得。
今年双11和往年一样,没有买什么东西,吃穿上感觉很好,没有什么缺的。
从校园里出来大概四个月了,这四个月的心路历程很曲折。
七月份那还是学校安排专业培训的时候,两周左右的python,从某培训机构请来的一个老师。当时我的心已经完全放飞了,因为在专业培训之前家里有个在HB银行工作的远房亲戚给我介绍了一份专业相关的工作,我去面试两次而且通过了,心里很高兴,尤其是当自己心里和别人比较时,自己后面已经有了去处就很高兴、美滋滋,现在看来却很可笑。两周的培训,相当不认真,点完名就走人,除了打rank、打球就没有做过其他的事情。身边的朋友们都在准备考研和找实习工作,我自己一个人每天玩的不亦乐乎。在学校培训完回家待了一周,和家里的朋友同样也是打rank、打球、吃 饭。
7月22号、周一,报道。那天起来的很早,洗漱、洗头,穿上在家新买的正装,坐公交来到平安南大街79号。办理入职手续、开通公司内部账号、分了公司宿舍的一个床位,所有的这些都是第一次经历,太新鲜了,唯一的感觉就是这个公司有点小,之前也没过多的了解,毕竟亲戚介绍的。头一天也没有上班,我又回去学校搬来了被褥、生活用品、书,公司宿舍是两室两厅的房子,算上我七个人住,为了给舍友留下一个好印象我打扫了一个多小时卫生,晚上在市里吃了一顿好的涮羊肉,逛了一圈超市就回去睡觉了。满怀期待。
23号我来到了平安北大街28号入职,领导来楼下接我上去,带我逛了机房、电池间、消防间,介绍认识了今天上班的同事,每天的具体工作就是机房巡检、以及夜间值班进行银行系统跑批。后来我才知道我这公司是外包公司,主要客户HB银行,我是属于运维人员,其实就是基础设施运维,看温湿度,检查UPS、空调漏水,时刻关注总、分行机房报警,夜间值班才是重头戏。领导带我逛完一圈之后跟我说:“你先上一三五,双休。”白天一天很闲,一小时去一次机房,半天去一次电池间,当天值班的哥哥给我一本系统跑批操作手册我就看了一天。为什么说晚上是重头戏呢,银行系统跑批应该是每个银行每天都要做的事情,以前人们都是手动轧账,现在是通过计算机批量轧账。各个系统之间都是有关联关系的,比如先完成A才能做B,所有网点都关机才能做C,完成B、C才能进行D……通常这一套完成下来要到凌晨三四点左右,还需要一小时去一次机房,基本通宵。为了避免手动操作计算机轧账出现失误,就有了一套专门的自动化轧账工具,我们就是鼠标点击执行,然后盯着报错,大部分问题通过重做来解决,个别问题需要随时联系系统负责人来远程解决,怪不得这个工作会被外包出来。
第一天上晚班我就发誓,我要离开这里,一分一秒都不想在这里呆着了。
好多朋友问,那你为什么还待了一个月。我是这样想的,我是普通院校普通专业的学生,在省内还可以,省外人家根本不知道你的学校(确实遇到了),既然来到这里了,不如先干着看一看再说吧,虽然我之前就做好了要从最简单最基础的工作干起,但是这样的工作我内心实在还是无法接受;卡内基在书中谈到过”使自己的工作变得有意义”这一话题,一是如果你”假装”对工作有兴趣,一点假装就会使你的兴趣成真,也可以减少你的疲劳;二是要不停的提醒你自己,对自己的工作感兴趣,就能使你不再忧虑。这两句话可以说是引领了我的思想,我不断朝着这两句话去想,确实我的心态会慢慢的变好起来,白天工作不忙我可以都拿来学习编程知识,每次去机房巡检都可以仔细看一排服务器机柜,几乎所有的机器我都没有见过,IBM小型机、扩展机柜、F5、Oracle一体机等等,网络结构和银行系统架构没有看懂,哈哈。我想这只不过是一个略带失败的开始罢了,惩罚我之前的贪玩。
8月19号,一个月时间,我准时辞职,离职表格一上午填完了,下午收拾好东西我迫不及待的离开了那里。回到学校,感觉自由、舒畅,大学生活是如此美好,同时我也是目标明确,我要去北京,我要找一个自己喜欢的云计算方向的实习工作,不论是大公司还是小公司,我想做我真正喜欢的事情,而不是”假装”感兴趣。回到学校,还没有开学,基本都是考研的同学,非常清净。
我计划先去实验室学习两周,在这期间也投一投工作。第二天起来跑跑步、吃完饭便去实验室学习,后面的每一天基本如此。投了工作没几天便有一家公司喊我电话面试,抓紧准备了两天,但是面试结果十分不理想,面试官是按照简历里写的东西逐渐深入的问,而我对于所有问题都是只能说上来一言半语,一旦涉及到原理性的东西我就一点说不上来了。例如docker,namespace、cgroup、unionfs我都说不上来,只会一些docker pull 、docker push、docker run这样的基本操作,一旦涉及到原理性的东西我就一点说不上来了,当时学习的时候听了一遍视频课感觉知道了就过了,实际自己去表述出来的时候脑子里空荡荡。面试的过程十分尴尬,虽然隔着手机但是真的是浑身上下的不自在。
总结了这次面试过程中的所有问题,以及所有原理性的讲解全部落到书面,感觉完全是为了面试而面试。在总结的过程中还会遇到相互关联的问题,比如明白网卡bonding之后对应的在交换机上是不是也要做相关的链路聚合配置。其实我一直感觉自己最大的问题是不会学习,没有自己的学习方法,效率低的一匹,在实验室这一年也只是安软件,并没有真正的去学习其背后的东西,没有自己的思考。我觉得这会是我转变的一个契机吧。
28号同方有云初试,我提前一天来到附近的一个青年旅社住下了,晚上吃了份抻面,按着导航来到同方科技广场,四栋高高的写字楼,灯火通明,心里很激动,很想到这样的地方工作学习,如果能到这里工作那回事多么让人自豪的事情。拍了几张照片,深呼吸了几口,感觉很好。回去的路上我一直在给自己加油,明天面试加油。回到住的地方,两室一厅的屋子里住了十五个人,很是拥挤。洗漱完又看了一遍笔记就躺下了,脑海里在幻想着以后在北京学习生活的每天都是怎样的,每天都要学什么呢,有空还要去找实验室的朋友们玩会,来自四线城市的我能否在这里立足呢?
早早起来,阳光很好,吃了个面包,比约定的时间早了一个多小时就到了,坐在马路边心里默背着自我介绍。面试的问题基本也都是基于简历中项目经历,还问了一些开放性的问题,比如该如何学习openstack等等。面试的结果我感觉一般,有些问题的解释不是很好,而且总是说一些大白话,很多专业名词到了嘴边就说不出来,组织语言的能力很差劲。其实心里感觉很遗憾,还是自己学的不扎实,对于自己的想法也表达不准确。
9月1号泰富酒店京东初试,下午才匆匆赶到,签到之后等待面试官叫号,面试场地的布置好像大型相亲会场。面试官真的是和蔼可亲,也十分客气,本来我还是有些紧张此时也放松了很多。递上简历,面试官问的问题也都比较简单,我回答的也很轻松,但是谈及到编程能力的时候我确实无话可说,基本没有接触过,面试官也是很真诚的建议我一定要提升自己的编码能力,有利于自己以后走得更远,最后提醒了好几遍复试的时间,面试过程很愉快,体验很好。心里很感谢这位面试官,可以看到他的真诚。晚上八点恰好又有腾讯后台开发在线笔试,匆匆赶到北京西站,在麦当劳简单吃了一口,笔试题目全是编程,貌似有五道吧,答得很不理想,编程是短板,但是本着认真对待每一次机会的态度坚持到了最后一刻交卷。最后搭上当天最后一班高铁回去学校。
准备了一天之后,9月3号京东复试、同方有云复试及HR面试。
京东复试让我很难受。没有问到我专业相关的问题,就是简单的聊天,比较严肃。问了问我大学的生活都是怎样度过的、问了我相比其他人来说有什么优势、问了我的学校是几本…然后推荐我去测试岗,说是入门门槛低,我应聘的是运维开发岗,应该是要进行岗位调剂,然后问我是否可以接受。当时我心里想的是希望您能放下成见,看看我的简历,问我几个问题,我能回答好当然nice
了,回答不好我回去可以继续总结继续学习。但是我最终还是没有勇气说出来,笑着说我能接受。一定要努力提升自己,不卑不亢。出了泰富酒店紧接着来到同方这边,复试比较简单,说了一下项目经历还有问了关于监控方面的问题,然后紧接着就是HR面试,过程挺愉快的,收到offer挺开心的。
回学校放松了一天,9月5号和瑀瑀一起来到北京参加京东HR面试,给我面试的姐姐看上去十分精明能干。主要问到了这么几个问题,一是你在项目中还有在学习过程中遇到过什么问题并且是怎样解决的;二是说一下你的优缺点以及与他人相比自己的优势在哪…回答的很乱,没有思路,这种问题不知道该怎么回答,没想过。面试官最后说我思想上缺少深度…
后面还有小米、深信服等公司的面试笔试完了就没结果了。回家待了几天,自己反思了一下这一段时间的面试。一是表达,在表达的时候要放慢语速,不要说得很快导致在一些问题上阐述不清晰,这样不但可以自己理清思路也让面试官听得清楚,还有就是不要重复说一段话以及结巴嘴,面试的时候要坐端正,自信且面带微笑;二是简历,在写简历的时候是有条理,个人总结、在校经历、项目经历、专业技能等等争取用四五个模块来展现自己每个模块内分一、二、三条,每条概述一件事情,不要超过三四行吧,针对不同的岗位要求,要对简历进行修改因为内容侧重点是不一样的。简历样式不要花里胡哨,力求样式简单朴素 ,内容丰富多彩,还有就是简历里面写的内容自己一定要熟悉,不要面试官勾出来一个点来问,自己却不知道简历里面有;最后也是最重要的一点,学习的时候一定要去学原理,不只是像部署上了httpd服务这么简单,httpd 的原理与配置文件,以及虚拟主机、高可用负载均衡、http与https、加密与认证等等,也就是发散性思维,为什么要去学习原理,一开始我还是处于背诵这样的阶段,直到我开始工作了才知道,当遇到一个问题的时候,除了根据经验还有看日志解决,还有就是通过原理入手一步步排查错误;另一方面了解原理之后一定会碰到类似项目的变种,原理一致,实现方式不同,再去学习的话我想应该事半功倍。
来到有云将近两个月了,公司规模小了一点,但是公司内部的氛围还是很好的,遇到问题大家会聚到一起讨论,上下级之间很融洽,同时之间关系也都很好,上级不会摆架子,我去问问题领导会很认真的讲解,对于我这个实习生来说还是有太多东西需要学习,这两个月的时间是很有意义的,后面继续努力。
这大概就是我七月份到现在的生活主线了,上面写道的经历和观点有我自身的局限性。我对于自己的评价是很一般,在面试过程中遇到了太多高手了,北京的高手也太多了,只希望自己能一直做自己喜欢的事情,不断进步,不断超过自己吧。
firewall-cmd语法
firewall-cmd
firewall-cmd是firewalld的主要命令行工具。它可用于获取有关firewalld的状态信息,获取运行时和永久环境的防火墙配置,以及更改这些信息。
根据所选策略,需要通过身份验证才能访问或更改firewalld配置。它仅在firewalld运行时才可用
常规参数
-h 打印简短的帮助文本并退出
-V 打印firewalld的版本字符串。此选项不能与其他选项组合使用
-q 不要打印状态消息
状态参数
–state 检查firewalld守护程序是否处于运行状态
–reload 重新加载防火墙规则并保留状态信息。当前的系统配置将成为新的运行时配置,如果当前配置未处于永久配置中会因重新加载而丢失
–complete-reload 完全重新加载防火墙,甚至netfilter内核模块。这会终止活动连接,此选项只应在防火墙出现严重问题时使用
–runtime-to-permanent 保存当前运行时配置并重写系统配置,该方法的工作原理是,在配置firewalld时只进行运行时配置更改,一旦对配置满意并测试了它的工作方式,就可以将其保存到系统配置中
拒绝日志参数
通过使用LogDenied选项,firewalld可以为拒绝的数据包添加简单的日志记录机制。这些是被拒绝或丢弃的数据包。
–get-log-denied 打印拒绝日志
–set-log-denied=value value的值可以为all,unicast,broadcast,multicast和off。默认设置为off,禁用日志记录。all为所有。这会改变运行时配置和系统配置,并会重新加载防火墙以开启日志规则。
系统选项
–permanent 用于设置系统选项,仅在系统重启或服务restart/reload后生效,如果不加该参数则只是运行时配置的一部分
Zone
–get-default-zone 打印连接和接口的默认区域
–set-default-zone=zone 为没有选择区域的连接和接口设置默认区域。也可以更改连接或接口默认区域。这会改变运行配置和系统配置
–get-active-zones 打印当前区域以及区域中使用的接口和源。该是与接口或源绑定的区域
[–permanent] –get-zones 将预定义的区域打印为空格分隔的列表(firewalld将网卡对应到不同的区域(zone),zone 默认共有9个:block、dmz、drop、external、home、internal、public、trusted、work
[–permanent] –get-services 将预定义的服务打印为空格分隔的列表
[–permanent] –get-icmptypes 将预定义的icmptypes打印为空格分隔的列表。
[–permanent] –get-zone-of-interface=interface 打印接口绑定的区域名称
[–permanent] –get-zone-of-source=source[/mask]|MAC|ipset:ipset 打印源绑定的区域
[–permanent] –info-zone=zone 打印指定Zone的相关信息
[–permanent] –list-all-zones 列出所有区域添加和开启的所有内容
–permanent –new-zone=zone 添加新的系统配置和空区域
–permanent –new-zone-from-file=filename [–name=zone] 从已准备的区域文件中添加新永久区域
–permanent –delete-zone=zone 删除现有的永久区域
–permanent –load-zone-defaults=zone 加载区域默认设置或报告NO_DEFAULTS错误
–permanent –path-zone=zone 打印区域配置文件的路径
–permanent –zone=zone –set-description=description 为区域添加描述信息
–permanent –zone=zone –get-description 打印区域描述信息
–permanent [–zone=zone] –get-target 获得永久的目标区域
–permanent [–zone=zone] –set-target=target 设定一个永久区域的目标。参数为:default, ACCEPT, DROP, REJECT
更改和查询区域的参数
本节中的选项只影响一个特定区域。如果与 –zone=zone选项一起使用,则会影响指定zone。如果省略该选项,则会影响默认区域(–get-default-zone)。
[–permanent] [–zone=zone] –list-all 列出在指定区域的所有内容
service
[–permanent] [–zone=zone] –list-services 列出区域中添加的服务
[–permanent] [–zone=zone] –add-service=service [–timeout=timeval] 为Zone添加指定服务。可以多次指定此选项。也可指定时间,规则将在指定的时间内处于活动状态,并在之后自动删除。timeval格式为10s,20m或1h。
–timeout不能与–permanent组合使用
[–permanent] [–zone=zone] –remove-service=service 从区域中删除服务
[–permanent] [–zone=zone] –query-service=service 查询是否为Znoe添加了服务。如果为真,返回0,否则返回1
port
[–permanent] [–zone=zone] –list-ports 列出区域中添加的端口,格式为”端口号/协议”
[–permanent] [–zone=zone] –add-port=portid[-portid]/protocol [–timeout=timeval] 将端口添加到区域,并设定超时时间
,可以是单个端口也可以是端口范围。协议可以是 tcp, udp, sctp , dccp等,–timeout不能与–permanent组合使用
[–permanent] [–zone=zone] –remove-port=portid[-portid]/protocol 从ZONE中删除端口
[–permanent] [–zone=zone] –query-port=portid[-portid]/protocol 查询是Znoe是否包含指定端口。如果为真,返回0,否则返回1
protocol
[–permanent] [–zone=zone] –list-protocols 列出Zone中包含的协议
[–permanent] [–zone=zone] –add-protocol=protocol [–timeout=timeval] 为Zone添加指定协议。可以多次指定此选项。也可指定时间,规则将在指定的时间内处于活动状态,并在之后自动删除。timeval格式为10s,20m或1h。
–timeout不能与–permanent组合使用
[–permanent] [–zone=zone] –remove-protocol=protocol 从ZONE中删除协议
[–permanent] [–zone=zone] –query-protocol=protocol 查询是Znoe是否包含指定协议。如果为真,返回0,否则返回1
source-port
[–permanent] [–zone=zone] –list-source-ports 列出区域中添加的源端口,格式为”端口号/协议”
[–permanent] [–zone=zone] –add-source-port=portid[-portid]/protocol [–timeout=timeval] 将源端口添加到区域,并设定超时时间
,可以是单个端口也可以是端口范围。协议可以是 tcp, udp, sctp , dccp等,–timeout不能与–permanent组合使用
[–permanent] [–zone=zone] –remove-source-port=portid[-portid]/protocol 从ZONE中删除源端口
[–permanent] [–zone=zone] –query-source-port=portid[-portid]/protocol 查询是Znoe是否包含指定源端口。如果为真,返回0,否则返回1
icmp-block
[–permanent] [–zone=zone] –list-icmp-blocks 列出Zone中的ICMP协议块
[–permanent] [–zone=zone] –add-icmp-block=icmptype [–timeout=timeval] 为Zone的icmp块添加icmptype,可以多次指定此选项。也可指定时间,规则将在指定的时间内处于活动状态,并在之后自动删除。timeval格式为10s,20m或1h。
–timeout不能与–permanent组合使用
[–permanent] [–zone=zone] –remove-icmp-block=icmptype 从Zone的icmp块中删除icmptype
[–permanent] [–zone=zone] –query-icmp-block=icmptype 查询是Zone中是否包含指定icmptype。如果为真,返回0,否则返回1
forward-ports
[–permanent] [–zone=zone] –list-forward-ports 列出Zone中的IPv4转发端口
[–permanent] [–zone=zone] –add-forward-port=port=portid[-portid]:proto=protocol[:toport=portid[-portid]][:toaddr=address[/mask]] [–timeout=timeval] 在Zone中添加端口转发,可以多次指定此选项。也可指定时间,规则将在指定的时间内处于活动状态,并在之后自动删除。timeval格式为10s,20m或1h。
–timeout不能与–permanent组合使用。
端口可以是单个端口号,也可以是端口范围portid-portid。协议可以是tcp、udp、sctp或dccp。目标地址是一个简单的IP地址。
[–permanent] [–zone=zone] –remove-forward-port=port=portid[-portid]:proto=protocol[:toport=portid[-portid]][:toaddr=address[/mask]] 删除端口转发
[–permanent] [–zone=zone] –query-forward-port=port=portid[-portid]:proto=protocol[:toport=portid[-portid]][:toaddr=address[/mask]] 查询端口转发,如果为真,返回0,否则返回1
masquerade
[–permanent] [–zone=zone] –add-masquerade [–timeout=timeval] 设置IPv4地址转换,可指定时间,规则将在指定的时间内处于活动状态,并在之后自动删除。timeval格式为10s,20m或1h。
[–permanent] [–zone=zone] –remove-masquerade 关闭Zone中的Ipv4地址转换,当其超时了也会被关闭
[–permanent] [–zone=zone] –query-masquerade 查询Zone中是否开启了IPv4地址转换,如果为真,返回0,否则返回1
rich-rule
[–permanent] [–zone=zone] –list-rich-rules 列出Zone中的rich-rule
[–permanent] [–zone=zone] –add-rich-rule=’rule’ [–timeout=timeval] 为Zone中添加rich-rule
[–permanent] [–zone=zone] –remove-rich-rule=’rule’ 删除 Zone中的rich-rule
[–permanent] [–zone=zone] –query-rich-rule=’rule’ 查询Zone中是否有rich-rule,如果为真,返回0,否则返回1
接口绑定参数
将接口绑定到Zone意味着此Zone设置用于限制通过接口的流量。
本节中的选项只影响一个特定区域。如果与 –zone=zone选项一起使用,则会影响指定zone。如果省略该选项,则会影响默认区域(–get-default-zone)。使用firewall-cmd –get-zones
[–permanent] [–zone=zone] –list-interfaces 列出绑定到Zone的接口
[–permanent] [–zone=zone] –add-interface=interface 绑定接口到Zone。如果接口受NetworkManager控制,则首先连接到接口更改其连接区域。如果失败,则在防火墙中创建区域绑定。对于不受NetworkManager控制的接口,firewalld尝试更改ifcfg文件中的区域设置(如果该文件存在)。
作为终端用户,在大多数情况下不需要这样做,当没有设定NM_CONTROLLED=no时,NetworkManager会自动根据ifcfg接口文件中的zone=option向Zone中添加接口,只有在没有/etc/sysconfig/network scripts/ifcfg接口文件的情况下才应该这样做。如果存在这样的文件,并且使用–add-interface选项将接口添加到区域中,请确保在这两种情况下区域是相同的,否则行为将是未定义的。
[–zone=zone] –change-interface=interface 如果接口受NetworkManager控制,则首先连接到接口更改其连接区域。如果失败,则在防火墙中创建区域绑定。对于不受NetworkManager控制的接口,firewalld尝试更改ifcfg文件中的区域设置(如果该文件存在)。.
更改接口绑定的区域。步骤是–remove-interface然后–add-interface。如果接口以前没有绑定到Zone,那么它类似于–add-interface
[–permanent] [–zone=zone] –query-interface=interface 查询接口是否和该Zone绑定
[–permanent] –remove-interface=interface 仅用于删除不受NetworkManager控制的接口,firewalld不会更改ifcfg文件中的区域设置
绑定源(source)的参数
将源绑定到Zone意味着此区域设置用于限制来自此源的流量。
源地址是IP地址或地址范围,要么是带有IPv4或IPv6掩码的网络IP地址,或者是MAC地址,或者是ipset: prefix。对于IPv4,掩码可以是网络掩码,也可以是普通数字。对于IPv6,掩码是一个普通的数字。不支持使用主机名。
[–permanent] [–zone=zone] –list-sources 列出绑定到Zone的源
[–permanent] [–zone=zone] –add-source=source[/mask]|MAC|ipset:ipset 将源绑定到Zone
[–zone=zone] –change-source=source[/mask]|MAC|ipset:ipset 改变区域中绑定的源
[–permanent] [–zone=zone] –query-source=source[/mask]|MAC|ipset:ipset 查询源是否在Zone中
[–permanent] –remove-source=source[/mask]|MAC|ipset:ipset 删除源
IPSet 参数
1 | firewall-cmd --get-ipset-types #打印出ipset类型 |
–permanent –new-ipset=ipset –type=type [–family=inet|inet6] [–option=key[=value]] 添加永久的ipset,以及指定各种参数
–permanent –new-ipset-from-file=filename [–name=ipset] 从文件中添加永久ipset配置
–permanent –delete-ipset=ipset 删除已存在的ipset配置
–permanent –load-ipset-defaults=ipset 加载ipset 默认配置或者报告NO_DEFAULTS
[–permanent] –info-ipset=ipset 打印ipset的信息
1 | ipset |
[–permanent] –get-ipsets 打印预定义的ipset
–permanent –ipset=ipset –set-description=description 为ipset添加描述
–permanent –ipset=ipset –get-description 打印ipset的描述
[–permanent] –ipset=ipset –add-entry=entry 为ipset添加新条目
Adding an entry to an ipset with option timeout is permitted, but these entries are not tracked by firewalld.
[–permanent] –ipset=ipset –remove-entry=entry 删除ipset中的一个条目
[–permanent] –ipset=ipset –query-entry=entry 查询ipset中是否包含指定条目。Querying an ipset with a timeout will yield an error. Entries are not tracked for ipsets with a timeout.
[–permanent] –ipset=ipset –get-entries 列出ipset的所有条目
[–permanent] –ipset=ipset –add-entries-from-file=filename 使用文件向ipset添加条目,对于文件中列出的条目在ipset中已经存在的时候,打印警告。以#号、分号开头的行以及空白行会被忽略
[–permanent] –ipset=ipset –remove-entries-from-file=filename 使用文件从ipset删除条目,对于文件中列出的条目在ipset中已经存在的时候,打印警告。以#号、分号开头的行以及空白行会被忽略
–permanent –path-ipset=ipset 打印ipset配置文件的路径
Service参数
此部分中的选项仅影响一个特定服务。
[–permanent] –info-service=service 打印Service相关信息
1 | service |
–permanent –new-service=service 系统配置中添加服务
–permanent –new-service-from-file=filename [–name=service] 通过文件项系统配置中添加服务
–permanent –delete-service=service 删除已存在的服务
–permanent –load-service-defaults=service 加载服务默认设置或者报告NO_DEFAULTS错误
–permanent –path-service=service 打印服务配置文件的路径
–permanent –service=service –set-description=description 为服务添加描述
–permanent –service=service –get-description 打印服务的描述
–permanent –service=service –add-port=portid[-portid]/protocol 向服务中添加端口
–permanent –service=service –remove-port=portid[-portid]/protocol 从指定的服务中移除某端口
–permanent –service=service –query-port=portid[-portid]/protocol 查询端口是否添加到服务中
–permanent –service=service –get-ports 列出服务中添加的端口
–permanent –service=service –add-protocol=protocol 向服务中添加协议
–permanent –service=service –remove-protocol=protocol 从服务中删除某协议
–permanent –service=service –query-protocol=protocol 查询服务中是否包含某协议
–permanent –service=service –get-protocols 列出服务中包含的协议
–permanent –service=service –add-source-port=portid[-portid]/protocol 向某服务中添加源端口
–permanent –service=service –remove-source-port=portid[-portid]/protocol 从某服务中删除源端口
–permanent –service=service –query-source-port=portid[-portid]/protocol 查询源端口是否添加到服务中
–permanent –service=service –get-source-ports 列出某服务中的添加的源端口
–permanent –service=service –add-module=module 向服务中添加模块
–permanent –service=service –remove-module=module 从服务中删除模块
–permanent –service=service –query-module=module 查询模块是否已经添加到服务
–permanent –service=service –get-modules 列出服务中添加的模块
–permanent –service=service –set-destination=ipv:address[/mask] 为某服务设置目的地址
–permanent –service=service –remove-destination=ipv 从某服务中删除目的地址
–permanent –service=service –query-destination=ipv:address[/mask] 查询目的地址是否存在于服务设置中
–permanent –service=service –get-destinations 列出服务中添加的目的地址
Internet Control Message Protocol (ICMP)类型选项
Options in this section affect only one particular icmptype.
1 | firewall-cmd --get-icmptypes #获取所有支持的ICMP类型 |
[–permanent] –info-icmptype=icmptype 打印有关ICMPtype 的信息
1 | [root@docker-study ~]# firewall-cmd --info-icmptype=bad-header |
–permanent –new-icmptype=icmptype 添加新的ICMPtype
–permanent –new-icmptype-from-file=filename [–name=icmptype] 用过文件添加新的ICMPtype
–permanent –delete-icmptype=icmptype 删除已存在的ICMPtype
–permanent –load-icmptype-defaults=icmptype 加载icmptype默认设置或报告NO_DEFAULTS错误
–permanent –icmptype=icmptype –set-description=description 为ICMPtype 设置新的描述
–permanent –icmptype=icmptype –get-description 打印指定ICMPtype的描述
–permanent –icmptype=icmptype –add-destination=ipv 在ICMPtype中开启目的地址,可以是ipv4 或 ipv6
–permanent –icmptype=icmptype –remove-destination=ipv 在ICMPtype中禁用目的地址,可以是ipv4 或 ipv6
–permanent –icmptype=icmptype –query-destination=ipv 返回在ICMPtype中是否开启ipv4 或ipv6目的地址
1 | [root@docker-study ~]# firewall-cmd --permanent --icmptype=bad-header --query-destination=ipv4 |
–permanent –icmptype=icmptype –get-destinations List destinations in permanent icmptype.
1 | [root@docker-study ~]# firewall-cmd --permanent --icmptype=bad-header --get-destinations |
–permanent –path-icmptype=icmptype 打印出icmptype配置文件的路径。
锁定(Lockdown)参数
如果本地应用程序或服务以根用户身份运行(例如:libvirt)或使用policykit进行身份验证,则它们可以更改防火墙配置。使用此功能,管理员可以锁定防火墙配置,以便只有锁定白名单上的应用程序才能请求防火墙更改。
锁定访问检查限制了正在更改防火墙规则的D-Bus方法。查询、列表和get方法不受限制。
锁定功能是firewalld用户和应用程序策略的一个非常轻量级的版本,默认情况下是关闭的。
–lockdown-on
启用锁定。注意 , 如果启用锁定时firewall-cmd不在锁定白名单中,则无法使用firewall-cmd再次禁用它,需要编辑firewalld.conf。这是运行时和永久性更改。
–lockdown-off 禁用锁定。这是运行时和永久性更改。
–query-lockdown 查询是否启用了锁定。如果启用了锁定,则返回0,否则返回1。
锁定白名单(Lockdown Whitelist)参数
该锁定白名单可以包括commands,contexts,users和user ids。
如果白名单上的命令条目以星号“*”结尾,那么以该命令开头的所有命令行都将匹配。如果没有“*”,则必须匹配绝对命令包含的参数。
用户root和其他用户的命令并不总是相同。示例:root使用 /bin/firewall-cmd,在Fedora上的普通用户使用 /usr/bin/firewall-cmd。
[ –permanent]–list-lockdown-whitelist-commands
列出白名单中的所有命令。
[ –permanent] –add-lockdown-whitelist-command=command
添加command到白名单。
[ –permanent] –remove-lockdown-whitelist-command=command
command从白名单中 删除。
[ –permanent] –query-lockdown-whitelist-command=command
查询是否command在白名单中。如果为true则返回0,否则返回1。
[ –permanent]–list-lockdown-whitelist-contexts
列出白名单中的所有环境。
[ –permanent] –add-lockdown-whitelist-context=context
添加context到白名单。
[ –permanent] –remove-lockdown-whitelist-context=context
从白名单中 删除context。
[ –permanent] –query-lockdown-whitelist-context=context
查询context是否在白名单中。如果为true则返回0,否则返回1。
[ –permanent]–list-lockdown-whitelist-uids
列出白名单中的所有用户ID。
[ –permanent] –add-lockdown-whitelist-uid=uid
添加uid到白名单。
[ –permanent] –remove-lockdown-whitelist-uid=uid
从白名单中 删除用户ID 。
[ –permanent] –query-lockdown-whitelist-uid=uid
查询用户uid标识是否在白名单中。如果为true则返回0,否则返回1。
[ –permanent]–list-lockdown-whitelist-users
列出白名单中的所有用户名。
[ –permanent] –add-lockdown-whitelist-user=user
添加user到白名单。
[ –permanent] –remove-lockdown-whitelist-user=user
从白名单中 删除用户。
[ –permanent] –query-lockdown-whitelist-user=user
查询user是否在白名单中。如果为true则返回0,否则返回1。
紧急参数
–panic-on 开启紧急模式,所有进出包都被丢弃,活动连接将超时。只有在网络环境出现严重问题时才启用此功能。例如,黑客入侵。
这是运行时配置的更改
–panic-off 禁用紧急选项
–query-panic 查询是否开启紧急模式
firewalld概念及配置项
概念
Firewall被设计为两层:核心层和D-BUS层。核心层负责处理firewall的配置和iptables, ip6tables, ebtables, ipset,module loader 等底层功能。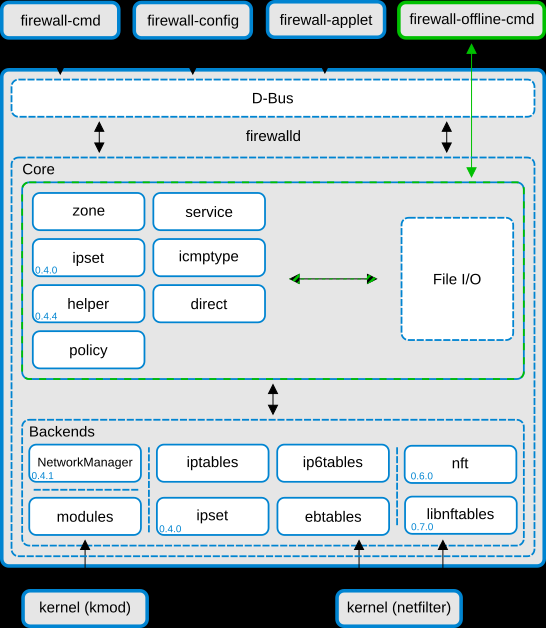
Firewalld D-Bus接口是更改和创建防火墙配置的主要方法。该接口被所有firewalld提供的在线工具所使用,例如firewall-cmd、firewall-config和firewall-applet。firewall-offline-cmd 并不与Firewalld通信,而是通过带有IO处理程序的Firewalld核心直接修改和创建firewalld配置文件。firewall-offline-cmd可以在Firewalld运行时使用,但不推荐使用它,因为它在大约5秒后才会更改防火墙中可见的永久配置。
Firewalld不依赖于NetworkManager组件,但是推荐使用。如果不使用NetworkManager,会有一些限制,例如:Firewalld不会收到关于网络设备重命名的通知。如果在network已经启动之后才启动firewalld,那么连接和手动创建的接口不会绑定到zone。使用firewall-cmd [–permanent] –zone=zone –add-interface=interface命令可以将接口添加到zone,但是要确保是否有/etc/sysconfig/network-scripts/ifcfg-*** 的网卡文件,ZONE和zone在这里不区分大小写,默认zone为空。
Firewalld支持znoe、service、ipset和icmptype
配置
关于目录
Firewall 支持两个配置目录:默认和后备配置,系统特定配置
默认和后备配置
/usr/lib/firewalld目录下包含icmptypes, services ,zones等默认和后备配置,Firewall所提供的晚间不应被修改,做出的更改会随着Firewall的更新而消失,Additional icmptypes, services and zones can be provided with packages or by creating files.
系统特定配置
/etc/firewalld中存储的系统或用户配置要么由系统管理员创建,要么使用firewalld的配置接口进行定制,要么手工创建。这些文件将覆盖默认文件。要手动更改预定义的 icmptypes, zones,services的设置,应将文件从默认配置目录复制到系统配置目录中,并相应地进行修改。
如果没有/etc/firewalld目录,Firewalld将使用firewall .conf中的默认配置和默认设置。
运行性配置和永久配置
配置被分为运行时配置和永久配置
运行时配置
运行时配置是实际有效的配置,应用于内核中的防火墙,Firewalld服务启动时,永久配置变为运行时配置,运行时配置中的更改不会自动保存到永久配置。运行时配置将随着Firewalld服务停止而丢失。
Firewalld重载时将用永久配置替换运行时配置。重新加载后,将恢复已更改的zone绑定。
永久配置
永久配置存储在配置文件中,将在每次机器重启或服务重新加载或重新启动时加载并成为新的运行时配置
运行时环境同样可用于创建符合需要的防火墙设置,当完成工作时可以和运行时状态一起迁移(When it is complete and working it can be migrated with the runtime to permanent migration).
可以使用firewall-config和firewall-cmd –runtime-to-permanent两条命令。
如果防火墙设置不工作,一个简单的firewalld reload/restart 将重新加载永久配置。
firewalld.conf
/etc/firewalld中的firewall .conf文件提供了firewalld的基本配置。如果不存在该文件或/etc/firewalld缺失,则将使用firewalld内部缺省值。
下面列出的为设置默认参数:
Default Zone
如果区域字符串为空,则使用默认区域。没有指定绑定到其他区域的所有内容都将由默认区域处理。
1 | # default zone |
Minimal Mark
这个最小值以下的标记可以自由使用,例如在direct接口中。如果需要更多的自由数则增加最小值。
1 | # Minimal mark |
Clean Up On Exit
如果设置为no或false,防火墙配置将不会在firewalld退出或停止时清除
1 | # Clean up on exit |
Lockdown
如果设置为”启用”,使用D-Bus接口的防火墙的更改将仅限于锁定白名单中列出的应用程序。锁定白名单文件是lockdown-white.xml。
1 | # Lockdown |
IPv6_rpfilter
对IPv6数据包执行反向路径筛选测试。如果对包的应答通过与包到达时相同的接口发送,那么将被接受,否则将被丢弃(防止DDOS和IP Spoofing)。IPv4的rp_filter是使用sysctl控制的。
1 | # IPv6_rpfilter |
Individual Calls
Do not use combined -restore calls, but individual calls. This increases the time that is needed to apply changes and to start the daemon, but is good for debugging.
1 | # IndividualCalls |
Log Denied
在缺省规则的输入、转发和输出链中添加日志记录规则,并在区域中添加最终的拒绝和删除规则。可能的值是: all, unicast, broadcast, multicast,off
1 | # LogDenied |
AutomaticHelpers
为了安全使用iptables和连接跟踪助手,建议关闭AutomaticHelpers。但是这可能会对使用netfilter helper作为/proc/sys/net/netfilter/nf_conntrack_helper中的sysctl设置的其他服务产生副作用。对于系统设置,将使用内核或sysctl中设置的默认值。可能的值是:yes、no、system。
1 | # AutomaticHelpers |
Docker 配置 TLS 认证
上一篇文章中的警告在这里展开,警告内容如下:
1 | WARNING: API is accessible on http://0.0.0.0:2376 without encryption. |
这样所有 ip 都能通过 docker -H <remote-dcoker-server_ip>:6379 [OPTION]命令与远程的 docker 守护进程通信,操作 docker 容器,生产上不提倡这种做法。
TLS
传输层安全性协议(英语:Transport Layer Security,缩写作TLS),及其前身安全套接层(Secure Sockets Layer,缩写作SSL)是一种安全协议,目的是为互联网通信提供安全及数据完整性保障。
CA是证书的签发机构。CA是负责签发证书、认证证书、管理已颁发证书的机关。它要制定政策和具体步骤来验证、识别用户身份,并对用户证书进行签名,以确保证书持有者的身份和公钥的拥有权。
CA 也拥有一个证书(内含公钥)和私钥。网上的公众用户通过验证 CA 的签字从而信任 CA ,任何人都可以得到 CA 的证书(含公钥),用以验证它所签发的证书。
证书包含以下信息:申请者公钥、申请者的组织信息和个人信息、签发机构 CA 的信息、有效时间、证书序列号等信息的明文,同时包含一个签名。
签名的产生算法:首先,使用散列函数计算公开的明文信息的信息摘要,然后,采用 CA 的私钥对信息摘要进行加密,密文即签名。
整个过程为:
1.服务器向CA机构获取证书,当浏览器首次请求服务器的时候,服务器返回证书给浏览器。(证书包含:公钥+申请者与颁发者的相关信息+签名)
2.浏览器得到证书后,开始验证证书的相关信息。
3.验证完证书后,如果证书有效,客户端是生成一个随机数,然后用证书中的公钥进行加密,加密后,发送给服务器,服务器用私钥进行解密,得到随机数。之后双方便开始用该随机数作为钥匙,对要传递的数据进行加密、解密。
我们需要在远程 docker 服务器使用CA 认证来生成客户端和服务端证书、服务器密钥,然后自签名,再颁发证书给需要连接远程 docker ademon 的客户端。
以上内容部分摘自https://www.cnblogs.com/yunlongaimeng/p/9417276.html
TLS验证
文档中指出:Docker over TLS should run on TCP port 2376.
服务端(CA机构、Docker Daemon在同一台服务器)
1 | #1.生成CA私钥ca-key.pem(rsa加密) |
使用scp将ca.pem,ca-key.pem发送到客户端服务器。其实应该先将服务器和客户端的申请文件发送至CA,由CA认证后向二者发放CA证书。
客户端
对于客户端身份验证,应创建客户端密钥和证书签名请求
1 | #1.生成客户端私钥client-key.pem |
默认安全连接
为简化操作,不必每次都对-H tcp://$host,–tls等参数进行调用,可以按下面步骤更改
服务端:将安全验证添加到/lib/systemd/system/docker.service中
1 | root@admin-dsq:~/.docker# ls # 此处为CA自签名证书、服务器证书、服务器密钥 |
客户端:如果要在默认情况下保护Docker客户端连接,可以将文件移动到.docker目录中,并设置 DOCKER_HOST和DOCKER_TLS_VERIFY变量
1 | [root@docker-study .docker]# ls #此处为CA自签名证书、客户端证书、客户端密钥 |
Docker现在默认安全连接
过程中出现的错误
- CA自签名证书默认路径为/root/.docker,服务器或客户端的CA证书和密钥也应该放在此目录下
1 | [root@docker-study ~]# docker --tlsverify -H 172.18.74.62 info |
- info:x509: cannot validate certificate for 172.18.74.62 because it doesn’t contain any IP SANs
1 | [root@docker-study /]# docker --tlsverify -H 172.18.74.62 info |
在指定证书的过程中要指定IP地址,参照:https://stackoverflow.com/questions/42116783/x509-cannot-validate-certificate-because-it-doesnt-contain-any-ip-sans 或者可以按照Docker文档中所给出的步骤即上述中的过程。
- 在客户端连接Docker Daemon时未成功,在Docker Daemon端报出如下信息:
1 | 客户端: |
Docker Daemon 使用 dockerd –tlsverify –tlscacert=/root/CA/ca.pem –tlscert=server-cert.pem –tlskey=server-key.pem -H 0.0.0.0:2376 启动后仅接受来自提供CA信任的客户端的连接,所以客户端也需要进行CA认证,二者所使用的CA自签名证书是一样的。
当ca.pem不同时有如下报错:
1 | [root@docker-study .docker]# docker info |
- 报错为私钥和公钥不匹配
1 | [root@docker-study client]# docker --tlsverify --tlscacert=../ca.pem --tlscert=../server-cert.pem --tlskey=key.pem -H 172.18.74.62 info |
- curl: (60) Peer’s Certificate issuer is not recognized.
1 | [root@docker-study ~]# curl https://172.18.74.62:2376/info |
报错为无法识别证书颁发者,因为是自己制作的证书,系统对CA没有认证,所以无法识别。
解决办法是将签发该证书的私有CA公钥cacert.pem文件内容,追加到/etc/pki/tls/certs/ca-bundle.crt下。
1 | #ubuntu下 |
- curl: (58) NSS: client certificate not found (nickname not specified)
1 | [root@docker-study .docker]# curl https://172.18.74.62:2376/version |
没有找到客户端认证,加–cert参数指定下路径就行了
- NSS error -8178 (SEC_ERROR_BAD_KEY)
1 | [root@docker-study .docker]# curl --cert /root/.docker/cert.pem https://172.18.74.62:2376/version |
参考:https://stackoverflow.com/questions/22499425/ssl-certificate-generated-with-openssl-not-working-on-nss?answertab=active#tab-top
我尝试了无密码和另外的des3 加密算法都没有成功,仍然是这个错误,待更新。
Docker远程访问
Docker目前采用了标准的C/S 架构,客户端和服务端既可以运行在一个机器上,也可以运行在不同的机器上并用过socket或者RESTful API来进行通信
1 | root@admin-dsq:/var/lib/docker# docker version |
1 | [root@docker-study ~]# docker version |
Server
Docker Daemon 一般在宿主机后台运行,作为服务端接受来自客户的请求(bulid、pull、run……)。
在设计上,Docker Daemon 是一个模块化的架构,通过专门的Engine模块来分发管理来自各个客户端的任务。
Docker端默认监听本地的unix:///var/run/docker.sock,只允许本地的root 或者 位于Docker用户组的成员访问。
Client
Docker客户端为用户提供一系列可执行命令,用户使用其与docker daemon 进行交互。
同样客户端默认通过本地的unix:///var/run/docker.sock套接字向server发送命令,如果server没有在监听默认的地址,则需要客户端在执行命令的时候显式指定服务端地址
配置远程访问
unix:///var/run/docker.sock方式(默认)
可以直接通过docker daemon -H 0.0.0.0:2375来进行监听端口的修改,但是修改后本地无法访问
第一个问题,没有daemon命令
1 | [root@docker-study ~]# docker daemon -H 0.0.0.0:2375 |
解决:
1 | [root@docker-study ~]# man docker | grep daemon |
看到里面又指出dockerd,继续看帮助手册
1 | NAME |
在描述中看到可以直接使用dockerd命令
又一个问题:
1 | [root@docker-study ~]# dockerd -H 0.0.0.0:2375 |
linux系统中/var/run/目录下的*.pid文件是一个文本文件,其内容只有一行,即某个进程的PID。.pid文件的作用是防止进程启动多个副本,只有获得特定pid文件(固定路径和文件名)的写入权限(F_WRLCK)的进程才能正常启动并将自身的进程PID写入该文件,其它同一程序的多余进程则自动退出。
原文https://blog.csdn.net/qq_29344757/article/details/79875693
1 | [root@docker-study ~]# systemctl stop docker |
此时另起一个终端
1 | [root@docker-study ~]# netstat -antp | grep 2375 #查看端口 |
回到上一个终端
1 | INFO[2019-04-01T15:37:43.503014754+08:00] API listen on [::]:2375 |
这种方法只是起到运行时的配置,并没有对配置文件进行修改,Ctrl+c 后,处理信号中断,2375端口关闭
tcp://host:port方式
admin-dsq为server,docker-study为client
在Server端对docker.server作如下修改
1 | root@admin-dsq:/var/lib/docker# cat /lib/systemd/system/docker.service |
1 | [root@docker-study ~]# docker -H 172.18.74.62 info |
现在使用命令docker info连接的就是服务端的docker了
关于第一个警告是此方法没有安全认证,任何对远程API的访问等同于对主机根目录的访问,在下一篇文章中在进行安全认证。
关于第二个警告:
摘自http://www.talkwithtrend.com/Question/123541?order=asc
根据错误提示,只是cgroups中的swap account没有开启。这个功能应该是用在 类似docker run -m=1524288 -it ubuntu /bin/bash 的命令,用来限制一个docker容器的内存使用上限,所以这里只是WARNING,不影响使用。
解决办法:
1 | When users run Docker, they may see these messages when working with an image: |
RESTful API方式
1 | [root@docker-study ~]# curl 172.18.74.62:2375/info |
详情见: https://docs.docker.com/develop/sdk/
https://docs.docker.com/engine/api/
https://docs.docker.com/registry/spec/api/
https://docs.docker.com/reference/dtr/2.6/api/
https://docs.docker.com/reference/ucp/3.1/api/
四种软件架构:单体架构、分布式架构、微服务架构、Serverless架构
一、单体架构
单体架构比较初级,典型的三级架构,前端(Web/手机端)+中间业务逻辑层+数据库层。这是一种典型的Java Spring mvc或者Python Django框架的应用。其架构图如下所示:

单体架构的应用比较容易部署、测试, 在项目的初期,单体应用可以很好地运行。然而,随着需求的不断增加, 越来越多的人加入开发团队,代码库也在飞速地膨胀。慢慢地,单体应用变得越来越臃肿,可维护性、灵活性逐渐降低,维护成本越来越高。下面是单体架构应用的一些缺点:
复杂性高: 以一个百万行级别的单体应用为例,整个项目包含的模块非常多、模块的边界模糊、 依赖关系不清晰、 代码质量参差不齐、 混乱地堆砌在一起。可想而知整个项目非常复杂。 每次修改代码都心惊胆战, 甚至添加一个简单的功能, 或者修改一个Bug都会带来隐含的缺陷。
技术债务: 随着时间推移、需求变更和人员更迭,会逐渐形成应用程序的技术债务, 并且越积 越多。“ 不坏不修”, 这在软件开发中非常常见, 在单体应用中这种思想更甚。 已使用的系统设计或代码难以被修改,因为应用程序中的其他模块可能会以意料之外的方式使用它。
部署频率低: 随着代码的增多,构建和部署的时间也会增加。而在单体应用中, 每次功能的变更或缺陷的修复都会导致需要重新部署整个应用。全量部署的方式耗时长、 影响范围大、 风险高, 这使得单体应用项目上线部署的频率较低。 而部署频率低又导致两次发布之间会有大量的功能变更和缺陷修复,出错率比较高。
可靠性差: 某个应用Bug,例如死循环、内存溢出等, 可能会导致整个应用的崩溃。扩展能力受限: 单体应用只能作为一个整体进行扩展,无法根据业务模块的需要进行伸缩。例如,应用中有的模块是计算密集型的,它需要强劲的CPU; 有的模块则是IO密集型的,需要更大的内存。 由于这些模块部署在一起,不得不在硬件的选择上做出妥协。
阻碍技术创新: 单体应用往往使用统一的技术平台或方案解决所有的问题, 团队中的每个成员 都必须使用相同的开发语言和框架,要想引入新框架或新技术平台会非常困难。
二、分布式应用
中级架构,分布式应用,中间层分布式+数据库分布式,是单体架构的并发扩展,将一个大的系统划分为多个业务模块,业务模块分别部署在不同的服务器上,各个业务模块之间通过接口进行数据交互。数据库也大量采用分布式数据库,如redis、ES、solor等。通过LVS/Nginx代理应用,将用户请求均衡的负载到不同的服务器上。其架构图如下所示:

该架构相对于单体架构来说,这种架构提供了负载均衡的能力,大大提高了系统负载能力,解决了网站高并发的需求。另外还有以下特点:
- 降低了耦合度:把模块拆分,使用接口通信,降低模块之间的耦合度。
- 责任清晰:把项目拆分成若干个子项目,不同的团队负责不同的子项目。
- 扩展方便:增加功能时只需要再增加一个子项目,调用其他系统的接口就可以。
- 部署方便:可以灵活的进行分布式部署。
- 提高代码的复用性:比如service层,如果不采用分布式rest服务方式架构就会在手机wap商城,微信商城,pc,android,ios每个端都要写一个service层逻辑,开发量大,难以维护一起升级,这时候就可以采用分布式rest服务方式,公用一个service层。
- 缺点 : 系统之间的交互要使用远程通信,接口开发增大工作量,但是利大于弊。
三、微服务架构
微服务架构,主要是中间层分解,将系统拆分成很多小应用(微服务),微服务可以部署在不同的服务器上,也可以部署在相同的服务器不同的容器上。当应用的故障不会影响到其他应用,单应用的负载也不会影响到其他应用,其代表框架有Spring cloud、Dubbo等。 其架构图如下所示:

易于开发和维护: 一个微服务只会关注一个特定的业务功能,所以它业务清晰、代码量较少。 开发和维护单个微服务相对简单。而整个应用是由若干个微服务构建而成的,所以整个应用也会被维持在一个可控状态。
单个微服务启动较快: 单个微服务代码量较少, 所以启动会比较快。
局部修改容易部署: 单体应用只要有修改,就得重新部署整个应用,微服务解决了这样的问题。 一般来说,对某个微服务进行修改,只需要重新部署这个服务即可。
技术栈不受限:在微服务架构中,可以结合项目业务及团队的特点,合理地选择技术栈。例如某些服务可使用关系型数据库MySQL;某些微服务有图形计算的需求,可以使用Neo4j;甚至可根据需要,部分微服务使用Java开发,部分微服务使用Node.js开发。
微服务虽然有很多吸引人的地方,但它并不是免费的午餐,使用它是有代价的。使用微服务架构面临的挑战。
运维要求较高:更多的服务意味着更多的运维投入。在单体架构中,只需要保证一个应用的正常运行。而在微服务中,需要保证几十甚至几百个服务服务的正常运行与协作,这给运维带来了很大的挑战。
分布式固有的复杂性:使用微服务构建的是分布式系统。对于一个分布式系统,系统容错、网络延迟、分布式事务等都会带来巨大的挑战。
接口调整成本高:微服务之间通过接口进行通信。如果修改某一个微服务的API,可能所有使用了该接口的微服务都需要做调整。
重复劳动:很多服务可能都会使用到相同的功能,而这个功能并没有达到分解为一个微服务的程度,这个时候,可能各个服务都会开发这一功能,从而导致代码重复。尽管可以使用共享库来解决这个问题(例如可以将这个功能封装成公共组件,需要该功能的微服务引用该组件),但共享库在多语言环境下就不一定行得通了。
四、Serverless架构
当我们还在容器的浪潮中前行时,已经有一些革命先驱悄然布局另外一个云计算战场:Serverless架构。

2014年11月14日,亚马逊AWS发布了新产品Lambda。当时Lambda被描述为:一种计算服务,根据时间运行用户的代码,无需关心底层的计算资源。从某种意义上来说,Lambda姗姗来迟,它像云计算的PaaS理念:客户只管业务,无需担心存储和计算资源。在此前不久,2014年10月22日,谷歌收购了实时后端数据库创业公司Firebase。Firebase声称开发者只需引用一个API库文件就可以使用标准REST API的各种接口对数据进行读写操作,只需编写HTML+CSS+JavaScrip前端代码,不需要服务器端代码(如需整合,也极其简单)。
相对于上两者,Facebook 在2014年二月收购的 Parse,则侧重于提供一个通用的后台服务。这些服务被称为Serverless或no sever。想到PaaS(平台即服务)了是吗?很像,用户不需要关心基础设施,只需要关心业务,这是迟到的PaaS,也是更实用的PaaS。这很有可能将会变革整个开发过程和传统的应用生命周期,一旦开发者们习惯了这种全自动的云上资源的创建和分配,或许就再也回不到那些需要微应用配置资源的时代里去了。
Serverless架构能够让开发者在构建应用的过程中无需关注计算资源的获取和运维,由平台来按需分配计算资源并保证应用执行的SLA(服务等级协议),按照调用次数进行计费,有效的节省应用成本。ServerLess的架构如上图所示。其优点如下所示:
低运营成本:在业务突发性极高的场景下,系统为了应对业务高峰,必须构建能够应对峰值需求的系统,这个系统在大部分时间是空闲的,这就导致了严重的资源浪费和成本上升。在微服务架构中,服务需要一直运行,实际上在高负载情况下每个服务都不止一个实例,这样才能完成高可用性;在Serverless架构下,服务将根据用户的调用次数进行计费,按照云计算pay-as-you-go原则,如果没有东西运行,你就不必付款,节省了使用成本。同时,用户能够通过共享网络、硬盘、CPU等计算资源,在业务高峰期通过弹性扩容方式有效的应对业务峰值,在业务波谷期将资源分享给其他用户,有效的节约了成本。
简化设备运维:在原有的IT体系中,开发团队即需要维护应用程序,同时还要维护硬件基础设施;Serverless架构中,开发人员面对的将是第三方开发或自定义的API 和URL,底层硬件对于开发人员透明化了,技术团队无需再关注运维工作,能够更加专注于应用系统开发。
提升可维护性:Serverless架构中,应用程序将调用多种第三方功能服务,组成最终的应用逻辑。目前,例如登陆鉴权服务,云数据库服务等第三方服务在安全性、可用性、性能方面都进行了大量优化,开发团队直接集成第三方的服务,能够有效的降低开发成本,同时使得应用的运维过程变得更加清晰,有效的提升了应用的可维护性。
更快的开发速度:这一点在现在互联网创业公司得到很好的体现,创业公司往往开始由于人员和资金等问题,不可能每个产品线都同时进行,这时候就可以考虑第三方的Baas平台,比如使用微信的用户认证、阿里云提供的RDS,极光的消息推送,第三方支付及地理位置等等,能够很快进行产品开发的速度,把工作重点放在业务实现上,把产品更快的推向市场。
但ServerLess架构也有其缺点:厂商平台绑定:平台会提供Serverless架构给大玩家,比如AWS Lambda,运行它需要使用AWS指定的服务,比如API网关,DynamoDB,S3等等,一旦你在这些服务上开发一个复杂系统,你会粘牢AWS,以后只好任由他们涨价定价或者下架等操作,个性化需求很难满足,不能进行随意的迁移或者迁移的成本比较大,同时不可避免带来一些损失。Baas行业内一个比较典型的事件,2016年1月19日Facebook关闭曾经花巨额资金收购的Parse,造成用户不得不迁移在这个平台中产生一年多的数据,无疑需要花费比较大的人力和时间成本。
成功案例比较少,没有行业标准:目前的情况也只适合简单的应用开发,缺乏大型成功案例的推动。对于Serverless缺乏统一的认知以及相应的标准,无法适应所有的云平台。
目前微服务架构在四种架构中处于主流地位,很多应用第一、第二种架构的企业也开始慢慢转向微服务架构。到目前为止微服务的技术相对于二三年前已经比较成熟,第四种架构将是未来发展的一种趋势。
原文链接:https://www.jianshu.com/p/e7b992a82dc0
分布式架构系列-负载均衡
面对大量用户访问、高并发请求,海量数据,可以使用高性能的服务器、大型数据库,存储设备,高性能Web服务器,采用高效率的编程语言比如(Go,Scala)等,当单机容量达到极限时,我们需要考虑业务拆分和分布式部署,来解决大型网站访问量大,并发量高,海量数据的问题。
从单机网站到分布式网站,很重要的区别是业务拆分和分布式部署,将应用拆分后,部署到不同的机器上,实现大规模分布式系统。分布式和业务拆分解决了,从集中到分布的问题,但是每个部署的独立业务还存在单点的问题和访问统一入口问题,为解决单点故障,我们可以采取冗余的方式。将相同的应用部署到多台机器上。解决访问统一入口问题,我们可以在集群前面增加负载均衡设备,实现流量分发。
负载均衡(Load Balance),意思是将负载(工作任务,访问请求)进行平衡、分摊到多个操作单元(服务器,组件)上进行执行。是解决高性能,单点故障(高可用),扩展性(水平伸缩)的终极解决方案。
本文是负载均衡详解的第一篇文章,介绍负载均衡的原理,负载均衡分类(DNS负载均衡,HTTP负载均衡,IP负载均衡,链路层负载均衡,混合型P负载均衡)。部分内容摘自读书笔记。
一、负载均衡原理
系统的扩展可分为纵向(垂直)扩展和横向(水平)扩展。纵向扩展,是从单机的角度通过增加硬件处理能力,比如CPU处理能力,内存容量,磁盘等方面,实现服务器处理能力的提升,不能满足大型分布式系统(网站),大流量,高并发,海量数据的问题。因此需要采用横向扩展的方式,通过添加机器来满足大型网站服务的处理能力。比如:一台机器不能满足,则增加两台或者多台机器,共同承担访问压力。这就是典型的集群和负载均衡架构:如下图:
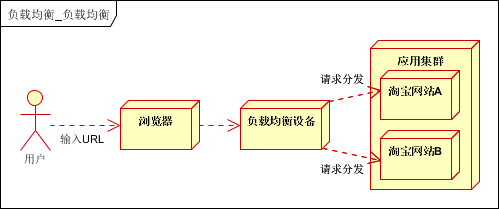
应用集群:将同一应用部署到多台机器上,组成处理集群,接收负载均衡设备分发的请求,进行处理,并返回相应数据。
负载均衡设备:将用户访问的请求,根据负载均衡算法,分发到集群中的一台处理服务器。(一种把网络请求分散到一个服务器集群中的可用服务器上去的设备)
负载均衡的作用(解决的问题):
解决并发压力,提高应用处理性能(增加吞吐量,加强网络处理能力);
提供故障转移,实现高可用;
通过添加或减少服务器数量,提供网站伸缩性(扩展性);
安全防护;(负载均衡设备上做一些过滤,黑白名单等处理)
二、负载均衡分类
根据实现技术不同,可分为DNS负载均衡,HTTP负载均衡,IP负载均衡,链路层负载均衡等。
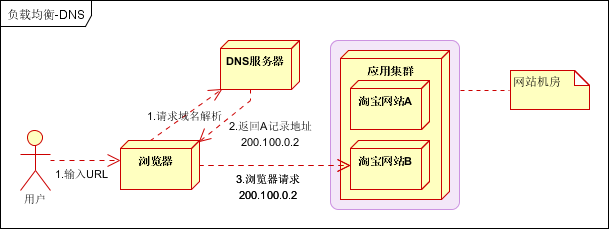
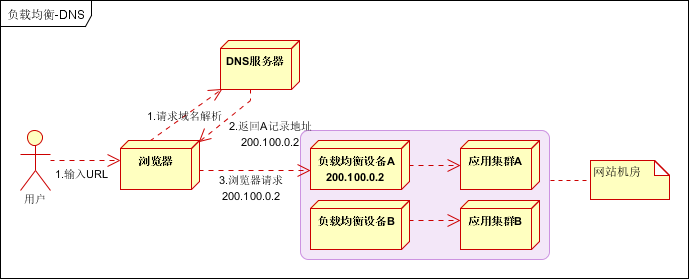
2.1 DNS负载均衡
最早的负载均衡技术,利用域名解析实现负载均衡,在DNS服务器,配置多个A记录,这些A记录对应的服务器构成集群。大型网站总是部分使用DNS解析,作为第一级负载均衡。如下图:
优点
1. 使用简单:负载均衡工作,交给DNS服务器处理,省掉了负载均衡服务器维护的麻烦
2.提高性能:可以支持基于地址的域名解析,解析成距离用户最近的服务器地址,可以加快访问速度,改善性能;
缺点
1.可用性差:DNS解析是多级解析,新增/修改DNS后,解析时间较长;解析过程中,用户访问网站将失败;
2.扩展性低:DNS负载均衡的控制权在域名商那里,无法对其做更多的改善和扩展;
3.维护性差:也不能反映服务器的当前运行状态;支持的算法少;不能区分服务器的差异(不能根据系统与服务的状态来判断负载)
实践建议
将DNS作为第一级负载均衡,A记录对应着内部负载均衡的IP地址,通过内部负载均衡将请求分发到真实的Web服务器上。一般用于互联网公司,复杂的业务系统不合适使用。如下图:
2.2 IP负载均衡
在网络层通过修改请求目标地址进行负载均衡。
用户请求数据包,到达负载均衡服务器后,负载均衡服务器在操作系统内核进程获取网络数据包,根据负载均衡算法得到一台真实服务器地址,然后将请求目的地址修改为,获得的真实ip地址,不需要经过用户进程处理。
真实服务器处理完成后,响应数据包回到负载均衡服务器,负载均衡服务器,再将数据包源地址修改为自身的ip地址,发送给用户浏览器。如下图:
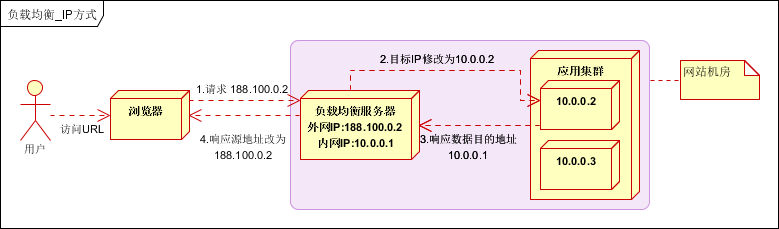
IP负载均衡,真实物理服务器返回给负载均衡服务器,存在两种方式:(1)负载均衡服务器在修改目的ip地址的同时修改源地址。将数据包源地址设为自身盘,即源地址转换(snat)。(2)将负载均衡服务器同时作为真实物理服务器集群的网关服务器。
优点:
在内核进程完成数据分发,比在应用层分发性能更好;
缺点:
所有请求响应都需要经过负载均衡服务器,集群最大吞吐量受限于负载均衡服务器网卡带宽;
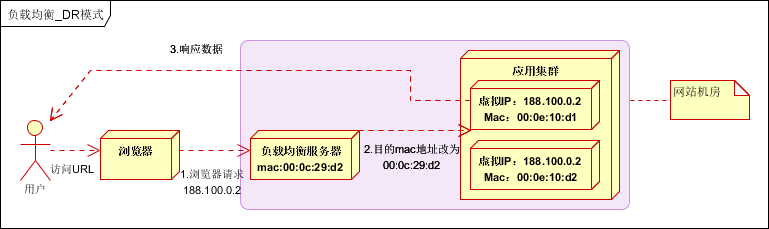
2.3 链路层负载均衡
在通信协议的数据链路层修改mac地址,进行负载均衡。
数据分发时,不修改ip地址,指修改目标mac地址,配置真实物理服务器集群所有机器虚拟ip和负载均衡服务器ip地址一致,达到不修改数据包的源地址和目标地址,进行数据分发的目的。
实际处理服务器ip和数据请求目的ip一致,不需要经过负载均衡服务器进行地址转换,可将响应数据包直接返回给用户浏览器,避免负载均衡服务器网卡带宽成为瓶颈。也称为直接路由模式(DR模式)。如下图:
优点:性能好;
缺点:配置复杂;
实践建议:DR模式是目前使用最广泛的一种负载均衡方式。
2.4 混合型负载均衡
由于多个服务器群内硬件设备、各自的规模、提供的服务等的差异,可以考虑给每个服务器群采用最合适的负载均衡方式,然后又在这多个服务器群间再一次负载均衡或群集起来以一个整体向外界提供服务(即把这多个服务器群当做一个新的服务器群),从而达到最佳的性能。将这种方式称之为混合型负载均衡。
此种方式有时也用于单台均衡设备的性能不能满足大量连接请求的情况下。是目前大型互联网公司,普遍使用的方式。
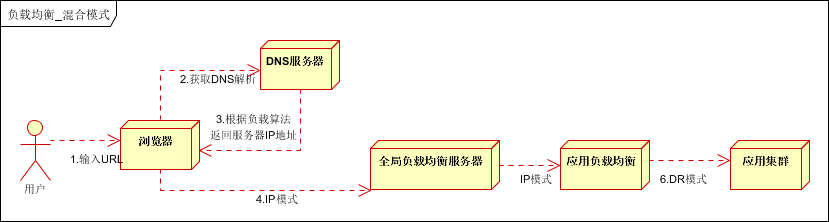
方式一,如下图:
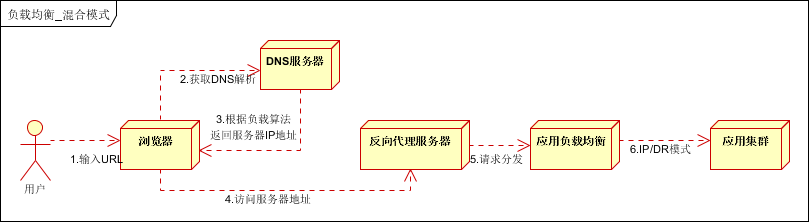
以上模式适合有动静分离的场景,反向代理服务器(集群)可以起到缓存和动态请求分发的作用,当时静态资源缓存在代理服务器时,则直接返回到浏览器。如果动态页面则请求后面的应用负载均衡(应用集群)。
方式二,如下图:
以上模式,适合动态请求场景。
因混合模式,可以根据具体场景,灵活搭配各种方式,以上两种方式仅供参考。
三、负载均衡算法
常用的负载均衡算法有,轮询,随机,最少链接,源地址散列,加权等方式;
3.1 轮询
将所有请求,依次分发到每台服务器上,适合服务器硬件同相同的场景。
优点:服务器请求数目相同;
缺点:服务器压力不一样,不适合服务器配置不同的情况;
3.2 随机
请求随机分配到各个服务器。
优点:使用简单;
缺点:不适合机器配置不同的场景;
3.3 最少链接
将请求分配到连接数最少的服务器(目前处理请求最少的服务器)。
优点:根据服务器当前的请求处理情况,动态分配;
缺点:算法实现相对复杂,需要监控服务器请求连接数;
3.4 Hash(源地址散列)
根据IP地址进行Hash计算,得到IP地址。
优点:将来自同一IP地址的请求,同一会话期内,转发到相同的服务器;实现会话粘滞。
缺点:目标服务器宕机后,会话会丢失;
3.5 加权
在轮询,随机,最少链接,Hash’等算法的基础上,通过加权的方式,进行负载服务器分配。
优点:根据权重,调节转发服务器的请求数目;
缺点:使用相对复杂;
四、硬件负载均衡
采用硬件的方式实现负载均衡,一般是单独的负载均衡服务器,价格昂贵,一般土豪级公司可以考虑,业界领先的有两款,F5和A10。
使用硬件负载均衡,主要考虑一下几个方面:
- 功能考虑:功能全面支持各层级的负载均衡,支持全面的负载均衡算法,支持全局负载均衡;
- 性能考虑:一般软件负载均衡支持到5万级并发已经很困难了,硬件负载均衡可以支持
- 稳定性:商用硬件负载均衡,经过了良好的严格的测试,从经过大规模使用,在稳定性方面高;
- 安全防护:硬件均衡设备除具备负载均衡功能外,还具备防火墙,防DDOS攻击等安全功能;
- 维护角度:提供良好的维护管理界面,售后服务和技术支持;
- 土豪公司:F5 Big Ip 价格:15w~55w不等;A10 价格:55w-100w不等;
缺点
- 价格昂贵;
- 扩展能力差;
小结
- 一般硬件的负载均衡也要做双机高可用,因此成本会比较高。
互联网公司一般使用开源软件,因此大部分应用采用软件负载均衡;部分采用硬件负载均衡。
比如某互联网公司,目前是使用几台F5做全局负载均衡,内部使用Nginx等软件负载均衡。
摘自: https://mp.weixin.qq.com/s/WG0oj-g8VuVfdIffgJhYWA
原作者:http://www.cnblogs.com/itfly8/p/5043435.html
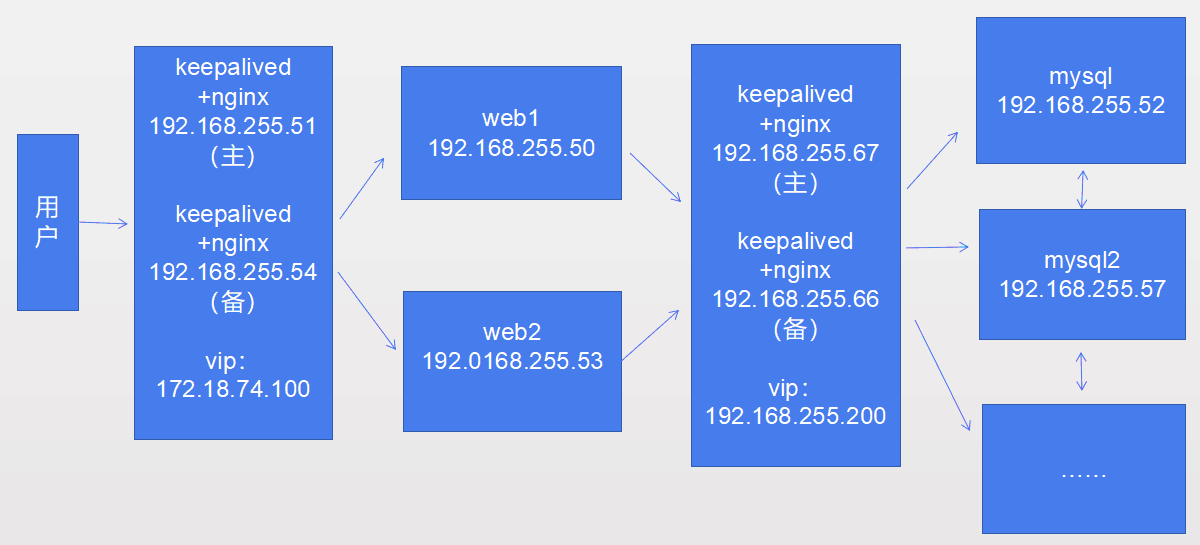
省科协高可用负载均衡集群
整个集群的架构如下图,服务器是exsi虚拟化。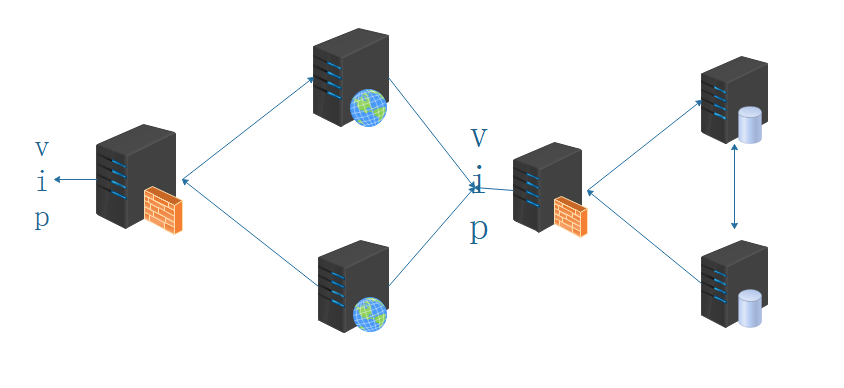
一、Firewall
在集群的配置过程中,我们的Firewall和SElinux是一直处于关闭的,感觉还是先配置上比较方便,说来惭愧 SElinux我不会(setenforce 0),在这里我就只打开Firewall了。
- 第一层Nginx监听的是80端口(也可以自定义),再将请求反向代理到web服务器的80端口(也可以自定义) ,所以他们都需要在Firewall上允许80端口的流量通过,即:
1 | firewall-cmd --zone=public --add-port=80/tcp |
- nginx高可用实现依靠的keepalived是以VRRP为基础,keepalived官方文档给出的组播地址是224.0.0.18,所以第一层和第三层的nginx的服务器上都需要在防火墙上允许vrrp组播的通过,即:
1 | firewall-cmd --direct --permanent --add-rule ipv4 filter INPUT 0 \ |
- MySQL集群必然要开启3306端口,第三层的Nginx也是在监听3306端口,即:
1 | firewall-cmd --zone=public --add-port=3306/tcp |
建议先看第五步网络存储挂载。
二、nginx高可用集群
nginx version: nginx/1.14.0,keepalived-2.0.7
编译安装nginx
wget http://www.zlib.net/zlib-1.2.11.tar.gz
wget https://jaist.dl.sourceforge.net/project/pcre/pcre/8.41/pcre-8.41.tar.gz
wget https://www.openssl.org/source/openssl-1.0.2o.tar.gz
wget http://labs.frickle.com/files/ngx_cache_purge-2.3.tar.gz
wget http://nginx.org/download/nginx-1.14.0.tar.gz
tar xvf …… 解压缩
1 | cd nginx-1.14.0.tar.gz |
配置nginx.conf
1 | #user nobody; |
nginx负载均衡功能实现依靠upstream模块,upstream模块应放于nginx.conf配置的http{}标签内,支持五种分配方式,轮询(默认)、weight、ip_hash三种原生方式,以及fair、url_hash两种第三方支持的方式。我用的是weight方式。
1 | proxy_pass http://backend; |
访问的是nginx服务器的地址即起到了反向代理的作用,代理web
接下来安装keepalive实现nginx集群的高可用。
编译安装keepalived
1 | cd keepalived-2.0.7 |
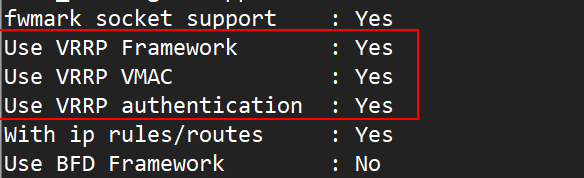
生成Makefile时有如下报错,需要另外安装libnl/libnl-3以支持IPv6,此处确实用不到,VRRP功能开启即可

配置keepalived
1 | ! Configuration File for keepalived |
keepalived是集群管理中保证集群高可用的一个服务软件,其功能类似于heartbeat,用来防止单点故障。
以VRRP协议为实现基础,可以认为是实现路由器高可用的协议,即将N台提供相同功能的路由器组成一个路由器组,这个组里面有一个master和多个backup,master上面有一个对外提供服务的vip(该路由器所在局域网内其他机器的默认路由为该vip),master会发组播,当backup收不到vrrp包时就认为master宕掉了,这时就需要根据VRRP的优先级来选举一个backup当master。这样的话就可以保证路由器的高可用了。
1 | nginx_check.sh如下: |
配置完成后Ngx-Master:
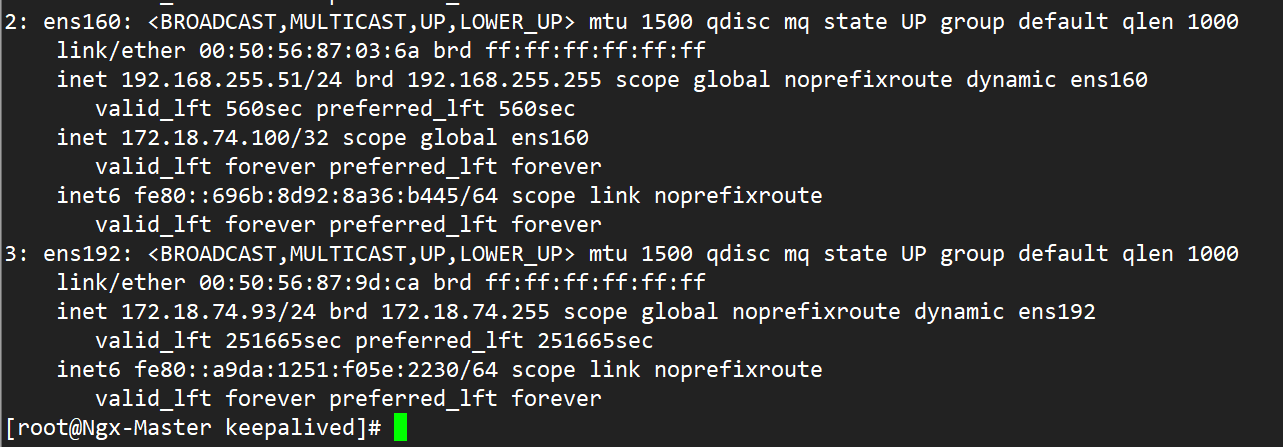
Ngx-Backup: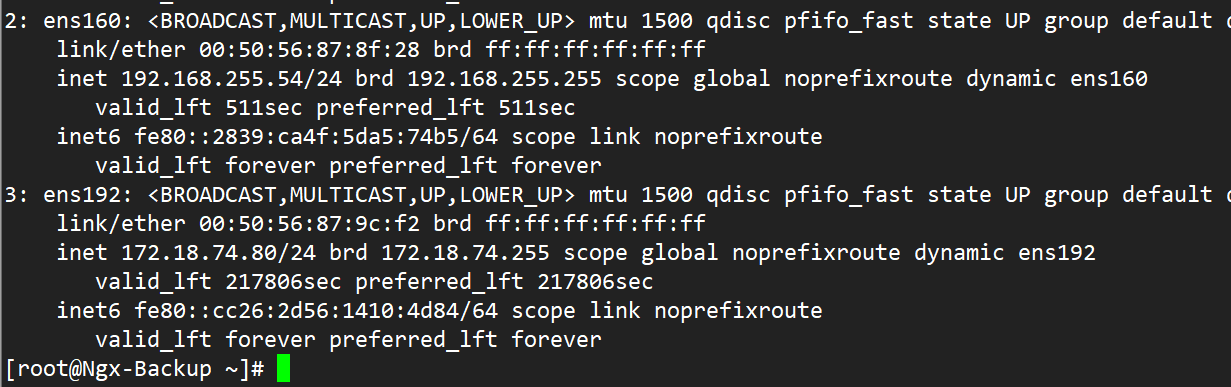
宕掉Master的网卡,vip直接转移到了Backup上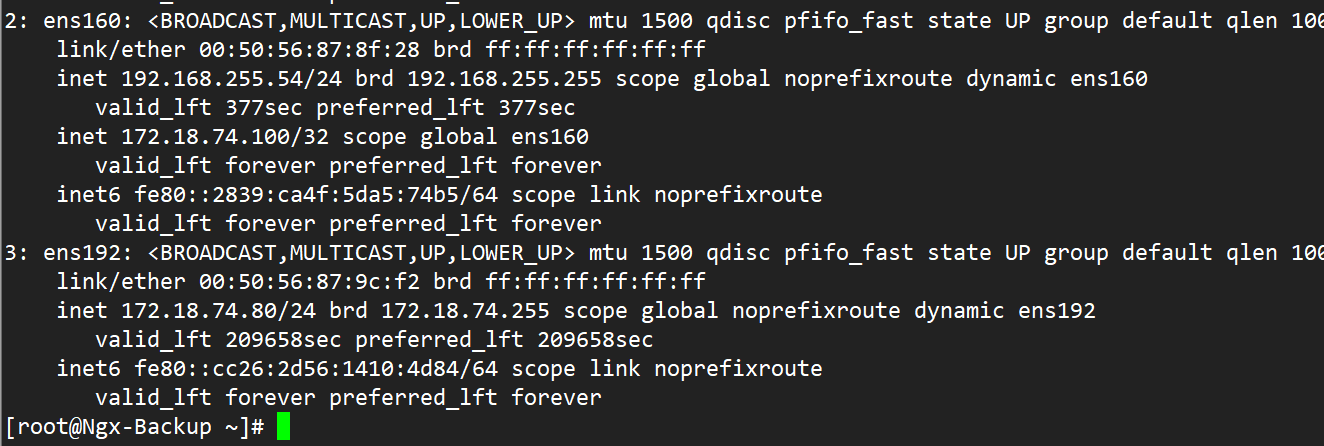
重启网卡后,vip回归到Master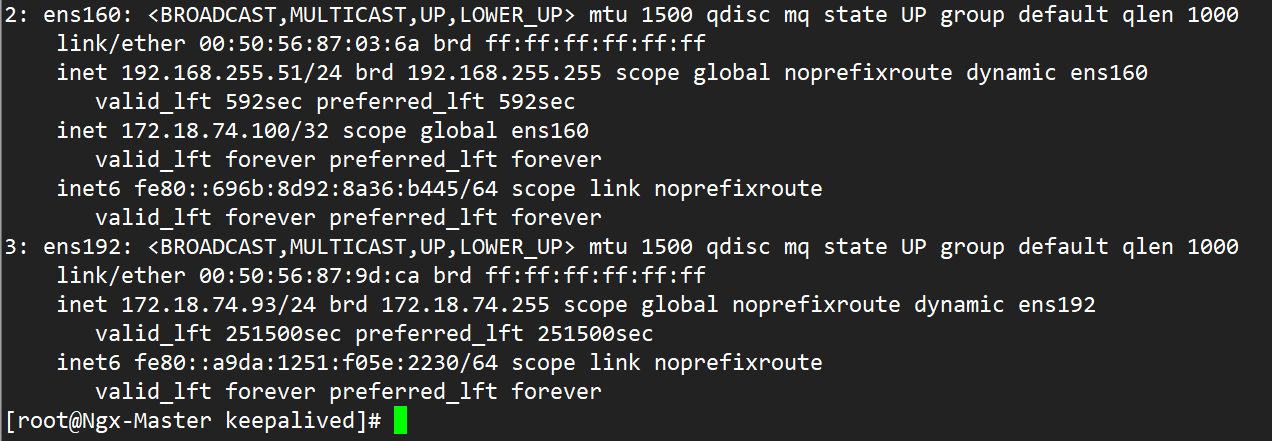
三、web 集群
这一部分其实很简单,在安装操作系统的时候我选的”Basic web server”,为了能验证web能提交数据到MySQL,写了一个PHP页面。
在连接数据库的时候,数据库地址是vip:192.168.255.200
1 | index.php |
1 | deal.php |
1 | coon.php |
下面的代码用来测试从数据库读取内容
1 | <?php |
如果两个web服务器中的页面不同,在提交表单的时候回显示无法找到。
最终效果为:
四、nginx高可用集群
nginx version: nginx/1.14.0,keepalived-2.0.7
与第一层原理相同,只不过反向代理的数据库,监听端口是3306
这里也会有一个Vip:192.168.255.200
配置Nginx
1 | nginx.conf |
配置keepalived
1 | keepalived.conf |
vip转移不再演示。
五、mysql双机热备集群
Server version: 5.6.43-log MySQL Community Server
源码安装mysql,不再展开。
mysql1:my.cnf
1 | # For advice on how to change settings please see |
mysql2:my.cnf
1 | # For advice on how to change settings please see |
web想要上传数据到数据库,首先需要使用web登录至数据库,然后MySQL中应当有已经创建好的数据库,库中要有表,用户权限等等。MySQL集群我们做的是双主,数据是同步的。
先配置双主吧,然后只用建一遍库就可以了。双主模型其实就是互为主从,主从同步复制原理分成三步:master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events ),slave将master的binary log events拷贝到它的中继日志(relay log),slave重做中继日志中的事件,将改变反映它自己的数据。
首先在两台mysql上创建用户张三 ,允许对方远程连接
1 | grant all privileges on *.* to zhangsan@192.168.255.52(192.168.255.57) identified by '123456'; |
先以MySQL1为主
MySQL1上(192.168.255.52 主):
1 | mysql> show master status; |
MySQL2上(192.168.255.57 从):
1 | mysql> change master to master_host='192.168.255.52',master_port=3306,master_user='zhangsan',master_password='123456',m aster_log_file='mysql-bin.000008',master_log_pos=120; |
再以MySQL2为主
MySQL2上(192.168.255.57 主):
1 | mysql> show master status; |
MySQL1上(192.168.255.52从);
1 | mysql> change master to master_host='192.168.255.57',master_port=3306,master_user='zhangsan',master_password='123456',m aster_log_file='mysql-bin.000006',master_log_pos=120; |
查看状态, Slave_IO_State 为等待主机事件;MySQL1主机显示192.168.255.57(即MySQL2)为主,在MySQL2上查看则相反;Slave_IO_Running: Yes;Slave_SQL_Running: Yes
1 | Mysql 1 : |
1 | MySQL 2: |
创建数据库
创建db-jd数据库,在库中创建tb_goods表,表中字段与PHP网页相对应,在mysql1中创建,mysql2中同步
1 | mysql> create database db_jd; |
授权允许web登陆
在两台MySQL服务器上创建web用户,允许远程登陆,并赋予db_jd数据库的权限1
2
3
4
5
6
7
8mysql> create user web@192.168.255.50 identified by '123456';
Query OK, 0 rows affected (0.37 sec)
mysql> grant all privileges on db_jd.* to web@192.168.255.50;
Query OK, 0 rows affected (0.12 sec)
mysql> create user web@192.168.255.53 identified by '123456';
Query OK, 0 rows affected (0.37 sec)
mysql> grant all privileges on db_jd.* to web@192.168.255.53;
Query OK, 0 rows affected (0.12 sec)
关于为什么不直接将权限赋给VIP,以及给Nginx服务器赋权,我认为归根到底还是web服务器的Apache与MySQL服务器MySQL -server之间通过套接字进行进程间通信,无论是vip还是Nginx只不过是中间的一座连接桥而已,实质上还是Apache与MySQL-Server通信。
在web插入数据进行测试,如下是在web1界面添加数据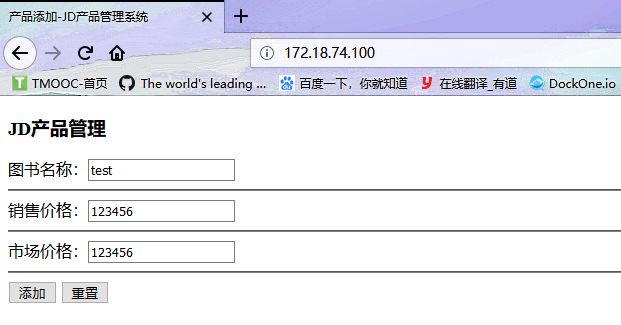
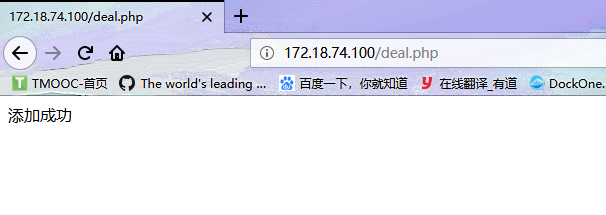
mysql1中可以看到插入的数据test
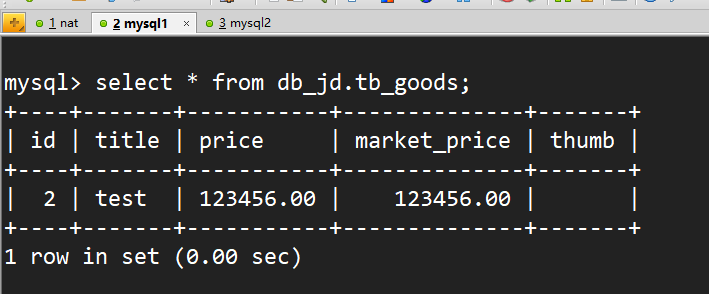
mysql2中同样有
六、网络链接NAS存储
输入ip访问NAS服务器的web页面,然后将nas中已经存在的文件夹挂载到mysql服务器的数据目录下即可。
使用mount挂载后,格式化了mysql数据目录下的文件,很郁闷,建议先挂载后再去安装mysql。
在NAS上开启NFS协议(NetworkFileSystem)。自带数据备份操作很简单。
1 | mount -t nfs -o nolock 172.18.74.39:/home/admin /var/lib/mysql |
虚拟化与云计算
虚拟化
虚拟化指对计算资源进行抽象的一个广义概念。虚拟化对上层应用或用户隐藏了计算资源的底层属性。它既包括使单个的资源(比如一个服务器,一个操作系统,一个应用程序,一个存储设备)划分成多个虚拟资源,也包括将多个资源(比如存储设备或服务器)整合成一个虚拟资源。
虚拟化技术是指实现虚拟化的具体的技术性手段和方法的集合性概念。虚拟化技术根据对象可以分成存储虚拟化、计算虚拟化、网络虚拟化等。计算虚拟化可以分为操作系统级虚拟化,应用程序级,和虚拟机管理器。虚拟机管理器分为宿主虚拟机和客户虚拟机。
虚拟化技术原理
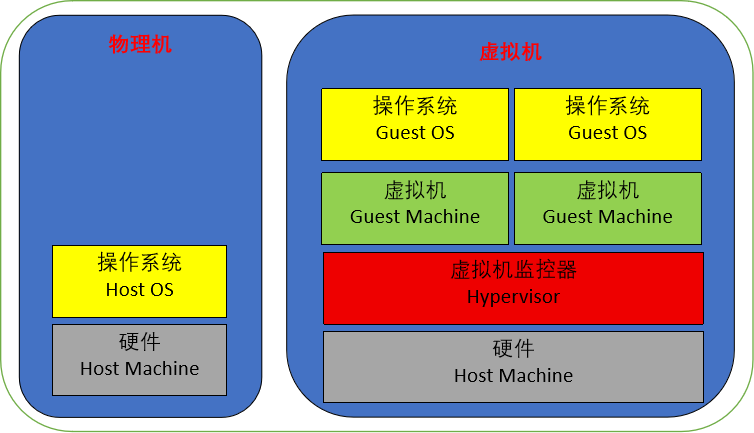
在操作系统中加入一个虚拟化层,一种位于物理机和操作系统之间的软件,允许多个操作系统共享一套基础硬件,也叫虚拟机监视器(Virtual Machine Monitor,即VMM)。该虚拟化层可以对主机的物理硬件资源(包括物理CPU、内存、磁盘、网卡、显卡等)进行封装和隔离,将其抽象为另一种形式的逻辑资源,然后提供给虚拟机使用。本质上,虚拟化层是联系主机和虚拟机的一个中间件。
虚拟机一般称为GuestOS(客户机),作为GuestOS载体的物理主机称为HostOS(宿主机)。
虚拟化技术的特点
同质:虚拟机的本质与物理机的本质相同。例如,二者CPU的ISA(指令集架构 Instruction Set Architecture)是相同的。
高效:虚拟机的性能与物理机接近,在虚拟机上执行的大多数指令有直接在硬件上执行的权限和能力,只有少数的敏感指令会由VMM来处理。
资源可控:VMM对物理机和虚拟机的资源都是绝对可控的。
移植方便:如果物理主机发生故障或者因为其他原因需要停机,虚拟机可以迅速移植到其他物理主机上,从而确保生产或者服务不会停止;物理主机故障修复后,还可以迅速移植回去,从而充分利用硬件资源。
虚拟化的实现层次
一般而言,CPU都可以分为用户态和内核态两种基本状态,而X86 CPU更是可以细分为Ring3~0四种状态(如图)。
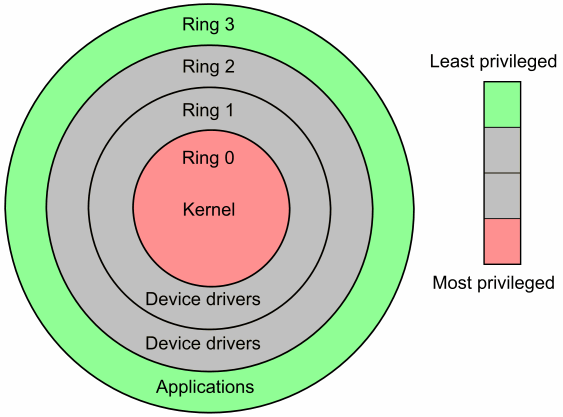
图片摘自http://www.cnblogs.com/pannengzhi/p/5790350.html
- Ring1和Ring2是驱动层,不涉及应用程序,与虚拟化的实现关系不大。
- Ring3用户态(User Mode):所有用户程序都运行在用户态,运行的代码受CPU的检查。程序调用硬件设备时,CPU通过专用接口调用核心态代码,然后对硬件设备进行操作。如果应用程序直接调用硬件设备,宿主机操作系统捕捉并触发异常报告。
- Ring0核心态(Kernel Mode):宿主机操作系统内核运行的模式,运行在核心态的代码可以无限制地对系统内存、设备驱动程序、网卡接口、显卡接口等外围设备进行访问。
虚拟化实现方式
全虚拟化(Full virtualization):
GuestOS可直接在VMM上运行而不需要对其本身做任何修改。全虚拟化的GuestOS具有完全的物理机特性。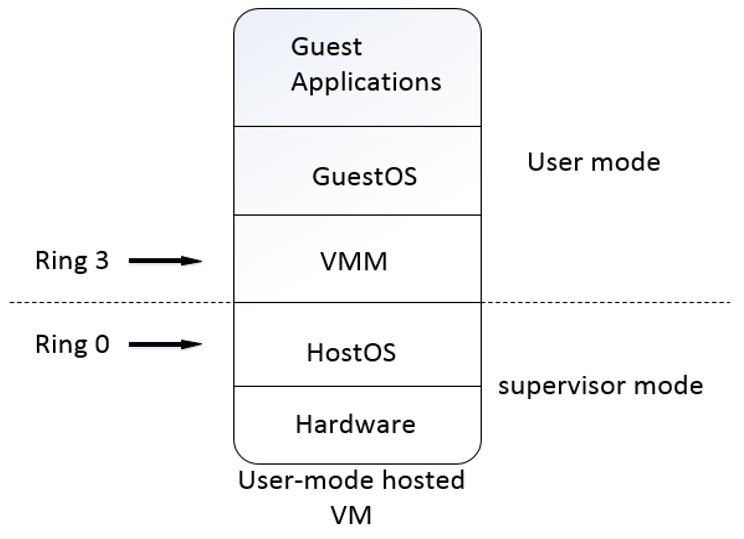
典型的全虚拟化软件有VMWare、Hyper-V、KVM-X86(复杂指令集)等。
半虚拟化(Paravirtualization):
半虚拟化需要GuestOS协助的虚拟化技术,因为在半虚拟化VMM中运行的GuestOS内核都经过了特别的修改,修改的主要是GuestOS内核指令集中包括敏感指令在内的内核态指令,从而高效地避免执行错误。
典型的半虚拟化软件如Xen、KVM-PowerPC(简易指令集)等。
除修改GuestOS内核以外,半虚拟化还有另一种实现方式,即在每一个GuestOS中安装特定的半虚拟化软件,如VMTools、RHEVTools等。
硬件辅助虚拟化(HVM)
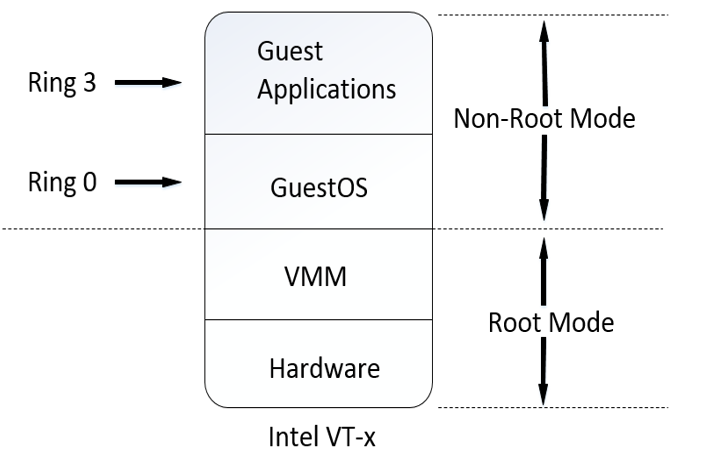
Intel提出并开发了由CPU直接支持的虚拟化技术,该技术引入了新的CPU运行模式和新的指令集,使VMM和GuestOS运行在不同的模式之下(VMM运行在Ring0之下的根模式;GuestOS运行在Ring0的非根模式),GuestOS运行于受控模式,其内核指令集中的敏感指令会全部陷入VMM,由VMM进行模拟。
CPU硬件辅助虚拟化技术解决了部分非内核态敏感指令的陷入模拟难题,模式切换时上下文的保存恢复工作也由硬件来完成,这样就大大提高了陷入模拟时上下文切换的效率。
目前,硬件辅助虚拟化技术的主要分类如下:
Intel VT-x:Intel的CPU硬件辅助虚拟化技术,包括IntelVTFlexPriority(Intel灵活任务优先级)、IntelVTFlexMigration(Intel虚拟化灵活迁移技术)和ExtendedPageTables(IntelVT扩展页表)三大功能。
AMD-V:AMD的CPU硬件辅助虚拟化技术,是针对X86处理器系统架构开发的一组硬件扩展和硬件辅助虚拟化技术。
内存虚拟化
内存虚拟化的映射(内存地址转换)涉及三类地址:
- 虚拟地址(VA):GuestOS提供给其应用程序使用的线性地址空间。
- 物理地址(PA):经VMM抽象的,虚拟机看到的伪物理地址。
- 机器地址(MA):真实的机器物理地址,即地址总线上出现的地址信号。
宿主机到虚拟机的内存地址映射关系如下:
- GuestOS:GuestOS负责VA到PA的映射。
- VMM:VMM负责PA到MA的映射。
总线虚拟化:
总线虚拟化技术可以将一块网卡分给若干个GuestOS使用,每个虚拟机分得网卡性能的1/N,这种技术直接把物理设备划分给GuestOS,无须经过VMM,性能高,接近真机。
容器虚拟化:
容器虚拟化是一种不同于虚拟机方式的虚拟化方法。容器虚拟化可以为应用程序提供隔离的运行空间,且一个容器内的变动不会影响其他容器。容器比虚拟机更轻量,效率更高,部署也更加快捷方便,但容器是将应用打包并以进程的形式运行在操作系统上的,应用和应用之间并非完全隔离,这是容器虚拟化的一个缺陷。
云计算
云计算(Cloud Computing)是一种新兴的商业计算模型。它将计算任务分布在大量计算机构成的资源池上,使各种应用系统能够根据需要获取计算力、存储空间和各种软件服务。通过服务器集群,包括计算服务器、存储服务器、宽带资源等虚拟计算资源的自我维护和管理,降低整个系统的单位处理能力成本。
云计算(Cloud Computing)是一种基于互联网的相关服务的增加、使用和交付模式,它依赖于虚拟化,通常会涉及通过互联网来提供动态易扩展且经常是虚拟化的资源。通过虚拟化技术,把服务器等硬件资源构建成一个虚拟资源池,从而实现共同计算和共享资源,就实现了云计算。
云计算的实现模式
IaaS–基础设施即服务:
由一些硬件、网络和操作系统资源集成。此模式下,用户不必自行采购硬件设备,也不用担心安装OS、配置防火墙、网络升级、更换硬件等事务,只需选择自己所需的硬件配置,如操作系统、带宽等,就可以使用相应的硬件资源。
PaaS–平台即服务:
PaaS在IaaS的基础上加入了中间件和数据库资源,用户选择PaaS时只要考虑习惯使用什么语言的数据库,然后关心程序的开发和部署即可。
SaaS–软件即服务:
在SaaS模式下,用户使用的软件并不需自己安装,也不用自己维护,而是只需要登录即可使用。
FaaS
可以广义的理解为功能服务化,也可以解释为函数服务化
见https://aws.amazon.com/cn/blogs/china/iaas-faas-serverless/
云平台的主要特性
可用性高:
当一台主机的虚拟化层出现故障时,云平台自动将上面的虚拟机迁移到另一虚拟化层上。控制面板服务器离线时,虽然不能对虚拟机进行任何管理操作,但虚拟机依旧可以正常运行。
管理灵活:
云平台具有高度的扩展性,可在云系统中任意添加和删除虚拟化层、数据存储设备和其他资源,如CPU和内存等。
用户管理方便:
云平台为用户提供精细的控制选项,设置不同类型的用户和用户组,定制不同用户与用户组的访问和功能。
负载均衡:
云平台的负载均衡功能,提高了应用程序的可用性和可扩展性。
安全可靠:
基础设施的虚拟机之间完全隔离,各自访问自己的硬盘。存储虚拟机的服务器上安装有反欺骗防火墙。在控制面板中可以给用户设置不同的角色,并为其配置不同级别的访问权限。
计费功能完善:
面向第三方的云平台有强大的计费功能,拥有完整的账单系统,支持多种货币类型,实现资源的计划使用和自动结算。
集成丰富的API:
云平台集成了多种应用软件接口,允许用户自行在云端进行应用开发。
支持移动接入:
云平台一般都支持iPhone/Android应用,用户可以通过移动设备连接云系统,管理自己的云资源和在云中的操作
虚拟化与云计算
虚拟化是云计算的关键技术之一,实现云计算必须使用虚拟化技术,实现资源的动态弹性分配。任何一个云计算管理平台,都是构建在虚拟化管理平台的基础之上的。
虚拟化资源使用需要管理员进行管理和分配,云计算是用用户自助管理和使用。
云计算完全解除了的软件和硬件耦合度,所有基础设施资源均虚拟化后通过资源池进行配额衡量,与硬件无关。虚拟化虽然实现了资源池化,但资源的分配仍旧需要与硬件存在一定程度上的关联。
HTTP请求方法
GET方法
GET是最常用的方法,GET 方法意思是获取被请求 URI(Request-URI)指定的信息(以实体的格式),常用于请求服务器发送某个资源。GET请求中不会呈现数据。
最常用于向服务器查询某些信息。必要时,可以将查询字符串参数追加到URL末尾,以便将信息发送给服务器。
使用GET请求时经常会发生的一个错误,就是查询字符串的格式有问题。查询字符串中每个参数的名称和值都必须使用encodeURLComponent()进行编码,然后才能放到URL的末尾;而且所有的名-值对都必须由(&)分离。
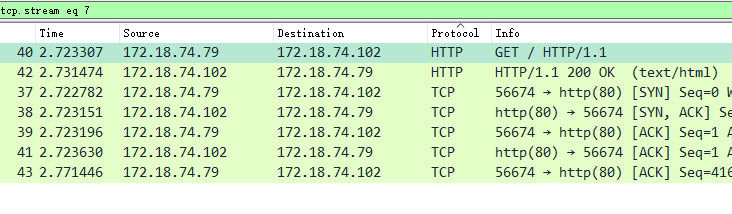
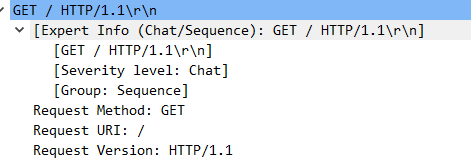
追踪HTTP流后,显示如下,响应报文中包含请求的页面
1 | GET / HTTP/1.1 |
HEAD方法
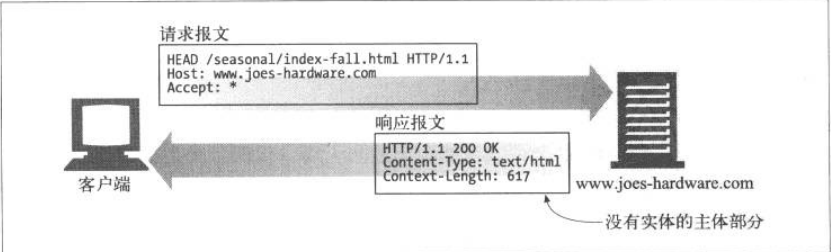
HEAD方法与GET方法的行为很类似,但在服务器响应中只会返回收首部,不会返回实体的主体部分。这就允许客户端在未获取实际资源的情况下,对资源首部进行检查。使用HEAD 可以:
- 在不获取资源的情况下了解资源的情况(例如,对类型的判断)
- 通过查看响应中的状态码,看看某个对象是否存在
- 通过查看首部,测试资源是否被修改
PUT方法
与GET从服务器读取文档相反,PUT方法会向服务器写入文档。有些发布系统允许用户创建Web页面,并用PUT直接将其安装到Web服务器上去。
PUT方法的语义是让服务器用请求的主体部分来创建一个由所请求的URL命名的新文档,或者如果那个URL已经存在的话,就用这个主体来替代它。
我猜测,如果在某公司的招聘网站提交简历应该会用到PUT方法,因为PUT用于向服务器上的资源中存储数据。
1 | PUT /personal-center/resumeInfo HTTP/1.1 |
POST方法
POST方法期初是用来向服务器输入数据的,实际上,通常会用他来支持HTML的表单。表单中填好的数据通常会被送给服务器,然后由服务器将其发送到它要去的地方(例如发送到数据库中存储)。POST用于向服务器发送数据。
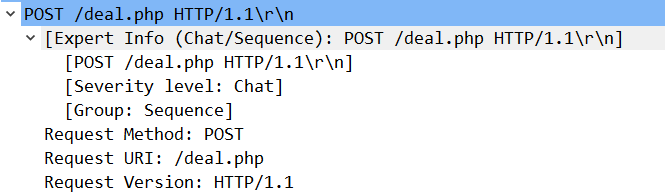
追踪HTTP流后。可以看到使用POST方法提交的数据
1 | POST /deal.php HTTP/1.1 |
DELECT方法
顾名思义,DELECT方法所做的就是请服务器删除请求URL所指定的资源。但是客户端应用程序无法保证删除操作一定会执行。因为HTTP规范允许服务器在不通知客户的端的情况下撤销操作。
如果响应里包含描述成功的实体,响应应该是 200(OK);如果 DELETE 动作还没有执行,应该以 202(已接受)响应;如果 DELETE 请求方法已经执行但响应不包含实体,那么应该以204(无内容)响应。
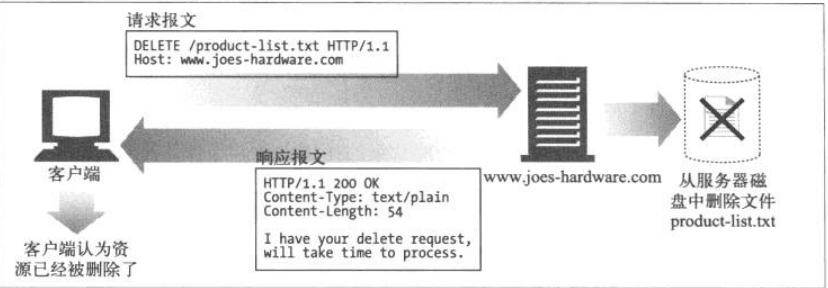
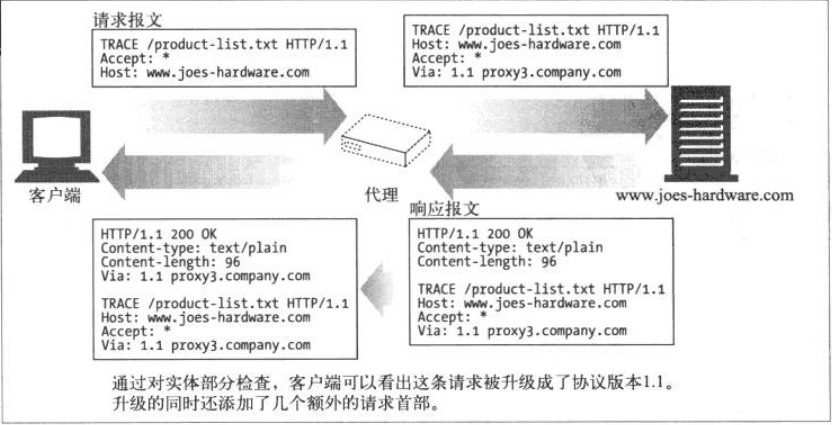
TRACE方法
客户端发起一个请求时,这个请求可能要穿过防火墙、代理、网关或其他一些应用程序。每个中间节点都可能会修改原始HTTP请求。TRACE方法允许客户端在最终将请求发送给服务器时看看它变成了什么样子。
TRACE请求会在目的服务器端发起一个”环回”诊断。行程最后一站的服务器会弹回一条TRACE响应,并在响应主体中携带它所收到的原始请求报文。这样客户端就可以查看在所有中间HTTP应用程序组成的请求/响应链上,原始报文是否以及如何被毁坏或修改过。
TRACE方法主要用于诊断,也就是说,用于验证请求是否如愿穿过了请求/响应链。它是一种很好的工具,可以用来查看代理和其他应用程序对客户请求所产生的效果。
尽管TRACE可以很方便的用于诊断,但它也存在缺点,他假定中间应用程序对各类不同的类型请求的处理方式是相同的。很多HTTP应用程序会根据方法的不同做出不同的事情,比如代理可能会将POST请求直接发给服务器,而将GET请求发送给另一个HTTP应用程序。TRACE并不提供区分这些方法的机制。通常中间应用程序会自行决定对TRACE 请求的处理方式。
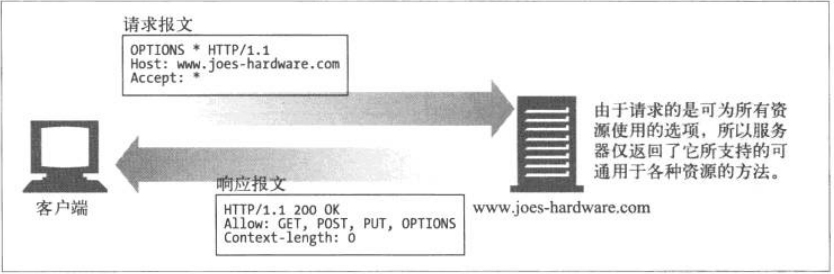
OPTION方法
OPTION方法请求Web服务器告知其支持的各种功能。可以询问服务器通常支持哪些方法,或者对某些特殊资源支持哪些方法。(有些服务器可能只支持对一些特殊类型对象使用特定操作)
这为客户端应用程序提供了一种手段,使其不用实际访问那些资源就能判定访问各种资源的最优方式。
CONNECT方法
HTTP1.1 协议规范保留了 CONNECT 方法,此方法是为了能用于能动态切换到隧道的代理
参考HTTP权威指南